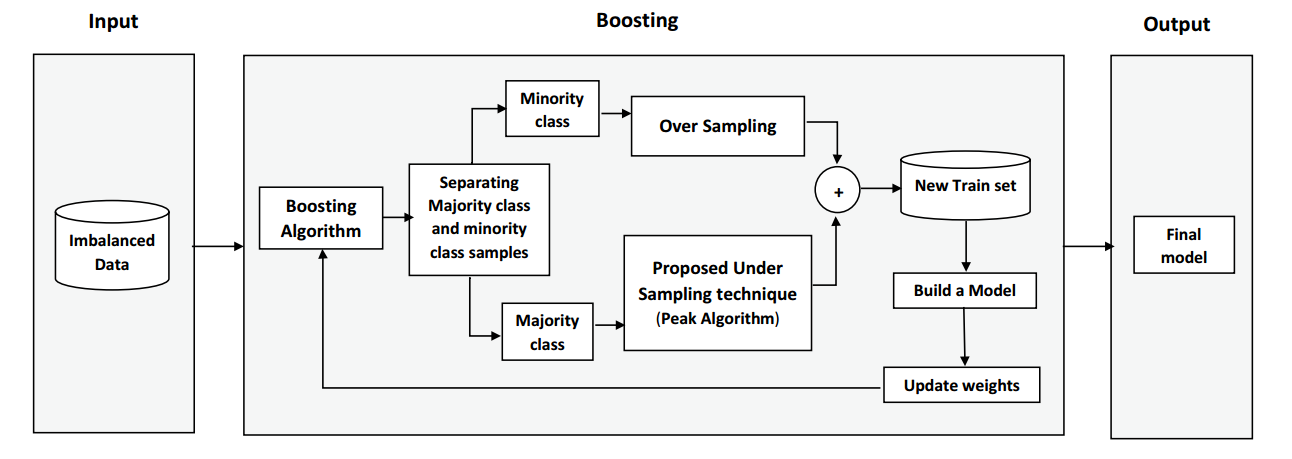
이번 게시글에는 PKDD 2003 컨퍼런스에서 발표된 SMOTEBoost 논문에 대해 작성하겠습니다.
Abstract
불균형 상황에서, 데이터 수가 적은 소수 클래스를 학습하게 되면 모델은 다수 클래스에 편향되게 학습이 되어서 다수 클래스에 대한 예측 정확도는 높아지지만, 소수 클래스에 대한 예측 정확도는 매우 낮아지는 문제가 흔히 발생합니다. 이를 해결하기 위해 대표적으로 소수 클래스를 생성하는 SMOTE기법을 사용하는데, SMOTE 기법은 소수 클래스 데이터를 Oversampling하기 위해 설계된 기법으로 불균형 상황에서 소수 클래스 예측 정확도를 높이는 데 효과적인 기법입니다.
이 논문에서는 불균형 데이터 셋에서 학습을 위해 SMOTE 기법과 Boosting 기법을 결합하여 새로운 접근법을 제시하고자 합니다.
SMOTEBoost는 소수 클래스를 생성함으로써 부스팅 알고리즘의 가중치 업데이트 방식에 영향을 미치며, 이를 통해 skewed distribution을 보완할 수 있게 합니다.
- SMOTE에 대해 혹시 모르신다면 이 글을 보고 오시는 것을 추천합니다!
[머신러닝] SMOTE(Synthetic Minority Over-sampling Technique)
이번 글에서는 SMOTE기법에 대해서 다뤄보겠습니다.SMOTE이번 게시글에서는 Imbalanced data 상황에서 Oversampling 응용기법인 SMOTE 기법에 대해 다뤄보겠습니다.기존의 Oversampling 기법은 minority class의 데
enjoy0life.tistory.com
SMOTEBoost Algorithm
기존의 부스팅 알고리즘은 오분류된 데이터에 가중치를 부여해 오분류된 데이터를 잘 학습할 수 있도록 작동합니다. 하지만, 데이터가 심각하게 불균형한 경우, 부스팅 알고리즘이 다수 클래스에 편향된 분포를 학습하게 되어 소수 클래스의 분류 성능이 낮아지는 문제가 발생합니다.
저자의 목표는 불균형 데이터에서 발생하는 편향(bias)을 줄이고, 소수 클래스의 데이터 경계를 더 잘 학습할 수 있는 모델을 만드는 것입니다.(편향을 줄이기 위해서는 데이터의 균형을 맞춰야 해서 가장 대표적인 기법인 SMOTE 기법을 사용해서 데이터를 생성한 것 같습니다.)
이제 SMOTE 기법과 Boosting 알고리즘을 어떻게 결합시켜 불균형 문제를 완화시킬 수 있었는지 살펴보도록 하겠습니다.
SMOTEBoosting 알고리즘
- SMOTE기법 적용
- 각 반복에서, 소수 클래스 데이터에 대해 SMOTE 기법을 적용해 데이터를 생성합니다.
- 데이터 분포 업데이트 $D_t$
- 각 반복에서 생성된 샘플은 분포 $D_t$에 추가되어 사용됩니다. 소수 클래스 데이터가 추가되어서 소수 클래스의 가중치를 증가시키는 효과를 얻을 수 있습니다.
- 가중치를 증가시킨다는 것은 소수 클래스가 추가 되었으니 분류기가 다수 클래스로 편향되어 예측하지 않고 소수 클래스에 대해 조금 더 학습을 잘 할 수 있도록 돕는다는 것 같습니다.
- 각 반복에서 생성된 샘플은 분포 $D_t$에 추가되어 사용됩니다. 소수 클래스 데이터가 추가되어서 소수 클래스의 가중치를 증가시키는 효과를 얻을 수 있습니다.
- SMOTE 데이터 삭제
- 각 반복단계에서 생성된 데이터는 제거되며 다음 부스팅단계에서 새롭게 생성된 데이터를 사용합니다.
- 생성된 데이터는 실제 데이터가 아니므로 노이즈가 될 수 있기 때문에 삭제하는 것 같습니다!
- 처음에는 생성된 데이터를 저장하여 계속 증가시키면 불균형이 완화되고 모델 성능이 좋아질거라고 생각했는데, SMOTEBoost의 목적을 확인해야 하는 것 같습니다.
- SMOTEBoost의 목적은 데이터 생성하여 균형을 맞추는 것이 아닌 소수 클래스의 패턴을 학습할 수 있는 기회를 늘리는 것이기 때문에 굳이 맞출필요는 없는 것 같습니다. 그리고 사실 SMOTE로 생성한 데이토 실제 소수 클래스가 아닌데, 소수 클래스라고 지정하고 학습하게 되면 오히려 노이즈로 작용할수도 있는 것 같습니다!
- Decision boundary
- 생성된 데이터는 Decision boundary 학습하는데 도움을 줍니다.
- 최종 분류기 학습
- 위 과정을 반복하여 최종 분류기를 학습하고, 데이터셋을 사용해 SMOTEBoost 적용하여 다른 기법들과 성능 비교
SMOTEBoost의 흐름을 설명해드렸고, 아래 사진은 알고리즘을 pseudo code로 작성한 것입니다.

Experimental Results
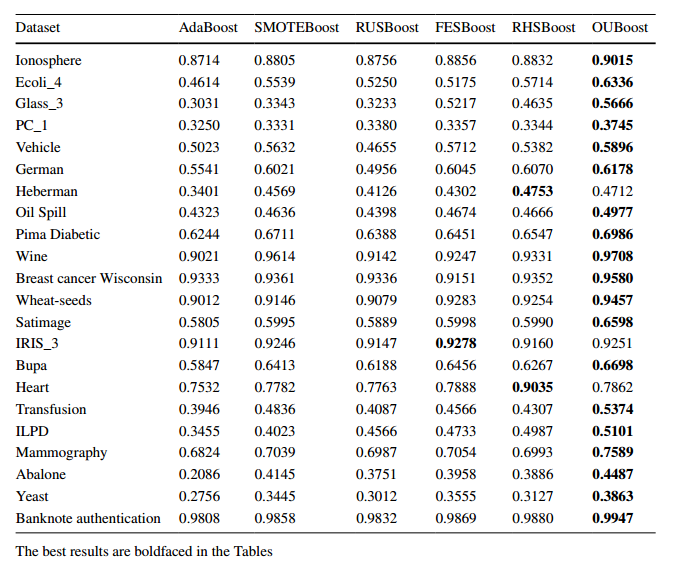
다음은 불균형한 데이터셋에서 SMOTEBoost의 성능을 다른 기법과 비교해보았습니다.

위 사진은 Mammography 데이터셋을 사용해서 F-value를 보았습니다. SMoteBoost에서 N=100으로 설정했을 때 분류기의 성능이 가장 좋은 것을 확인할 수 있습니다.
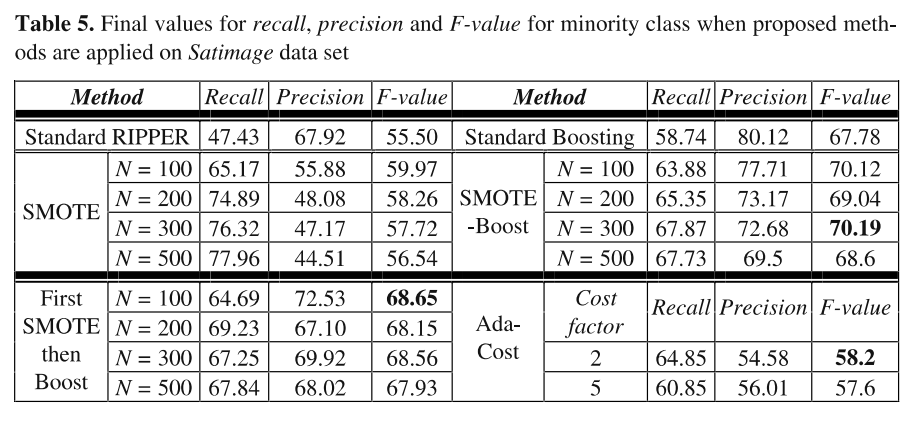
다음은 Satimage 데이터셋을 사용하여 F-value를 보았는데, 이때는 N=300으로 설정했을 때 성능이 가장 좋은 것을 확인할 수 있습니다.
이처럼 SMOTEBoost 모델이 기존의 SMOTE기법보다 성능이 좋은 것을 알 수 있으며 생성하는 숫자는 데이터셋마다 다른 것 같습니다.
확실히 SMOTE 기법만 사용하는 것보단 Boosting 모델을 결합하여 쓰면 성능이 좋은것을 알 수 있습니다.(아마도 부스팅의 목적이 오분류된 데이터를 더 잘 분류할 수 있도록 하는것이 목적이니까 소수 클래스를 잘 분류하는 모델을 만들어야하는 목적과 부합해서 좋은 시너지를 낼 수 있는 것 같습니다!)
참고문헌
'논문 리뷰 > Machine Learning' 카테고리의 다른 글
| OUBoost: boosting based over and under sampling technique for handling imbalanced data (1) | 2024.11.18 |
|---|---|
| [논문 리뷰] Double random forest(DRF) (1) | 2024.10.16 |