이번에는 2020년에 Machine Learning 저널에 게재된 Double random forest 논문에 대해 다뤄보겠습니다.
Double random forest 논문은 Random forest 모델을 보완해서 성능을 조금 더 향상시킨 모델입니다.
생각보다 되게 간단하고 참신한 아이디어 인 것 같아요!
Random forest에서 트리를 생성할 때 부트스트랩을 사용하여 모든 데이터가 사용되지 않는다는 점을 이용하여 Double random forest는 트리를 생성할 때 모든 데이터를 사용해 노드가 다양하게 학습 할 수 있도록 하는것이 이 논문의 Key point라고 보시면 될 것 같습니다. 아래에서 조금 더 자세하게 설명하겠습니다.
Abstract
Random forest는 parallel 앙상블 기법 중 가장 인기있는 방법론입니다. Random forest는 nodesize(hyperparameter) 최소화 하여 트리를 학습시킬 때 예측 성능이 가장 좋다고 합니다.
그러면 저자는 node size를 최소화 하면서 더 큰 트리를 만들 수 있다면 성능이 좋아지지 않을까? 라는 생각에 Double random forest를 제안했습니다.
이 방법론은 처음 트리를 생성할 때 부트스트랩 샘플링(루트 노드에서만)을 수행하는 Random forest와 다르게, 트리를 생성할 때 모든 데이터셋을 학습시키고 각 노드에서 부트스트랩 샘플링을 수행하여 트리의 다양성을 증가시키고자 합니다.
실제로 Double random forest 모델이 Random forest보다 정확도가 높다는 것을 확인하였습니다. 그러면 저자가 제안한 방법론을 pseudo code와 함께 살펴보면서 이해해보도록 하겠습니다.
Double Random Forest(DRF)
이제 Double random forest가 어떻게 작성되어있는지 자세하게 살펴보도록 하겠습니다.
아래 사진은 DRF 알고리즘의 pseudo code입니다.

이해하기 쉽도록 예를 들어서 설명하도록 하겠습니다.
전체 데이터가 100개 있다고 하겠습니다.
- Double random forest는 트리를 학습할 때 전체 데이터를 사용합니다. Random forest에서는 부트스트랩 샘플링을 통해서 트리를 학습했습니다.(부트스트랩 샘플링을 통해 중복된 샘플이 뽑힐 수 있으니 데이터가 DRF 보다는 다양하지 않을 수 있습니다.)
- 트리에서 한개의 sample이 뽑히지 않을 확률
- $\lim\limits_{n\rightarrow\infin}(1-\frac{1}{n})^n=e^{-1}$≈ 0.368
- 전체 데이터를 사용하여 루트노드에서 분할하고 난 후 두 개의 자식노드가 생기게 되는데 이때 각 노드에서 부트스트랩 샘플링을 사용해서 데이터를 뽑아 새로운 분할기준을 찾습니다.
이때 두 개의 자식노드에 각 50개씩 분할되었다고 가정하겠습니다.- 1번 자식노드 : 50개의 샘플
- 2번 자식노드 : 50개의 샘플
- 최적의 분할 과정을 계속해서 수행하는데, 만약 분할된 데이터가 전체 데이터의 10%보다 많지 않으면 부트스트랩 과정을 중단하고 원래 데이터로 분할과정을 수행합니다.
위 과정을 반복하여 트리를 만들어 분류기를 학습하게 됩니다. 그리고 Test data에는 투표 방식을 통해 가장 많이 투표가 된 레이블로 예측을 하게 됩니다.
알고리즘이 Random forest와 크게 다르지 않죠! 전체 데이터셋을 사용하여 더 큰 트리를 만드는 아이디어가 참신하다고 느꼈습니다.
Experimental Results
저자가 만든 DRF 모델과 RF 모델의 성능 차이를 한번 확인해보겠습니다.
mnist데이터를 활용하여 6번의 Test accuracy를 Box plot으로 확인하였고, 결과는 다음과 같습니다.

확실히 루트노드에서 더 많은 데이터를 사용할수록 다양한 트리를 학습할 수 있어서 성능이 좋아진 것을 확인할 수 있습니다.
또한 아래 사진은 200개 트리에서 터미널(최종) 노드의 평균 수와 표준편차를 나타내고 있습니다.
확실히 DRF가 노드의 수가 훨씬 많네요! 위에서 노드 크기가 클수록 예측 성능이 좋다고 하였으니 성능이 더 좋은게 납득이 가네요.

다음은 각 데이터셋에 RF모델과 DRF모델이 유의적으로 차이가 있는지 ANOVA 분석을 수행했습니다.
P-value가 유의수준 5%하에서 매우 작은 값을 가지기 때문에 두 모델은 통계적으로 차이가 있다고 볼 수 있습니다. 즉, DRF가 통계적으로 더 정확하다고 볼 수 있습니다.


마지막으로 두 모델의 computing times을 비교했습니다.
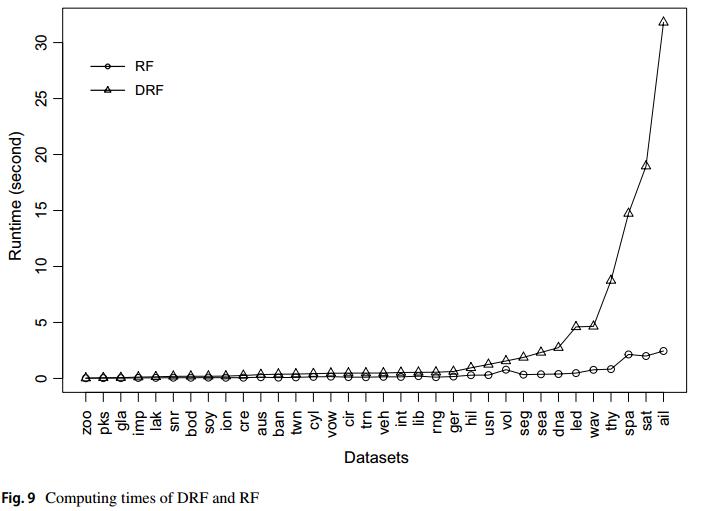
우측으로 갈수록 데이터셋의 크기가 매우 큰데, 데이터 셋이 클수록 DRF의 Runtime이 확실히 오래걸리는 것을 볼 수 있습니다.
감사합니다!
참고문헌
- Double Random forest : https://link.springer.com/article/10.1007/s10994-020-05889-1
'논문 리뷰 > Machine Learning' 카테고리의 다른 글
| SMOTEBoost : Improving Prediction of the Minority Class in Boosting (1) | 2024.11.18 |
|---|---|
| OUBoost: boosting based over and under sampling technique for handling imbalanced data (1) | 2024.11.18 |