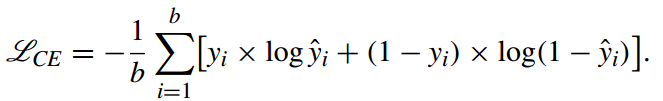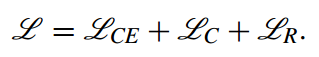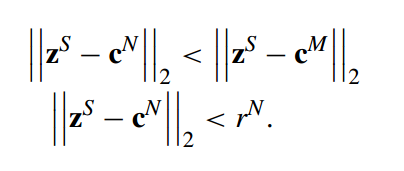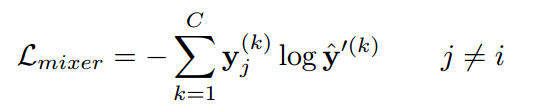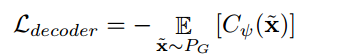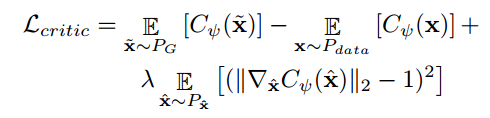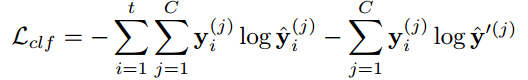이번 게시글에는 PKDD 2003 컨퍼런스에서 발표된 SMOTEBoost 논문에 대해 작성하겠습니다.
Abstract
불균형 상황에서, 데이터 수가 적은 소수 클래스를 학습하게 되면 모델은 다수 클래스에 편향되게 학습이 되어서 다수 클래스에 대한 예측 정확도는 높아지지만, 소수 클래스에 대한 예측 정확도는 매우 낮아지는 문제가 흔히 발생합니다. 이를 해결하기 위해 대표적으로 소수 클래스를 생성하는 SMOTE기법을 사용하는데, SMOTE 기법은 소수 클래스 데이터를 Oversampling하기 위해 설계된 기법으로 불균형 상황에서 소수 클래스 예측 정확도를 높이는 데 효과적인 기법입니다.
이 논문에서는 불균형 데이터 셋에서 학습을 위해 SMOTE 기법과 Boosting 기법을 결합하여 새로운 접근법을 제시하고자 합니다.
SMOTEBoost는 소수 클래스를 생성함으로써 부스팅 알고리즘의 가중치 업데이트 방식에 영향을 미치며, 이를 통해 skewed distribution을 보완할 수 있게 합니다.
기존의 부스팅 알고리즘은 오분류된 데이터에 가중치를 부여해 오분류된 데이터를 잘 학습할 수 있도록 작동합니다. 하지만, 데이터가 심각하게 불균형한 경우, 부스팅 알고리즘이 다수 클래스에 편향된 분포를 학습하게 되어 소수 클래스의 분류 성능이 낮아지는 문제가 발생합니다.
저자의 목표는 불균형 데이터에서 발생하는 편향(bias)을 줄이고, 소수 클래스의 데이터 경계를 더 잘 학습할 수 있는 모델을 만드는 것입니다.(편향을 줄이기 위해서는 데이터의 균형을 맞춰야 해서 가장 대표적인 기법인 SMOTE 기법을 사용해서 데이터를 생성한 것 같습니다.)
이제 SMOTE 기법과 Boosting 알고리즘을 어떻게 결합시켜 불균형 문제를 완화시킬 수 있었는지 살펴보도록 하겠습니다.
SMOTEBoosting 알고리즘
SMOTE기법 적용
각 반복에서, 소수 클래스 데이터에 대해 SMOTE 기법을 적용해 데이터를 생성합니다.
데이터 분포 업데이트 $D_t$
각 반복에서 생성된 샘플은 분포 $D_t$에 추가되어 사용됩니다. 소수 클래스 데이터가 추가되어서 소수 클래스의 가중치를 증가시키는 효과를 얻을 수 있습니다.
가중치를 증가시킨다는 것은 소수 클래스가 추가 되었으니 분류기가 다수 클래스로 편향되어 예측하지 않고 소수 클래스에 대해 조금 더 학습을 잘 할 수 있도록 돕는다는 것 같습니다.
SMOTE 데이터 삭제
각 반복단계에서 생성된 데이터는 제거되며 다음 부스팅단계에서 새롭게 생성된 데이터를 사용합니다.
생성된 데이터는 실제 데이터가 아니므로 노이즈가 될 수 있기 때문에 삭제하는 것 같습니다!
처음에는 생성된 데이터를 저장하여 계속 증가시키면 불균형이 완화되고 모델 성능이 좋아질거라고 생각했는데, SMOTEBoost의 목적을 확인해야 하는 것 같습니다.
SMOTEBoost의 목적은 데이터 생성하여 균형을 맞추는 것이 아닌 소수 클래스의 패턴을 학습할 수 있는 기회를 늘리는 것이기 때문에 굳이 맞출필요는 없는 것 같습니다. 그리고 사실 SMOTE로 생성한 데이토 실제 소수 클래스가 아닌데, 소수 클래스라고 지정하고 학습하게 되면 오히려 노이즈로 작용할수도 있는 것 같습니다!
Decision boundary
생성된 데이터는 Decision boundary 학습하는데 도움을 줍니다.
최종 분류기 학습
위 과정을 반복하여 최종 분류기를 학습하고, 데이터셋을 사용해 SMOTEBoost 적용하여 다른 기법들과 성능 비교
SMOTEBoost의 흐름을 설명해드렸고, 아래 사진은 알고리즘을 pseudo code로 작성한 것입니다.
Experimental Results
다음은 불균형한 데이터셋에서 SMOTEBoost의 성능을 다른 기법과 비교해보았습니다.
위 사진은 Mammography 데이터셋을 사용해서 F-value를 보았습니다. SMoteBoost에서 N=100으로 설정했을 때 분류기의 성능이 가장 좋은 것을 확인할 수 있습니다.
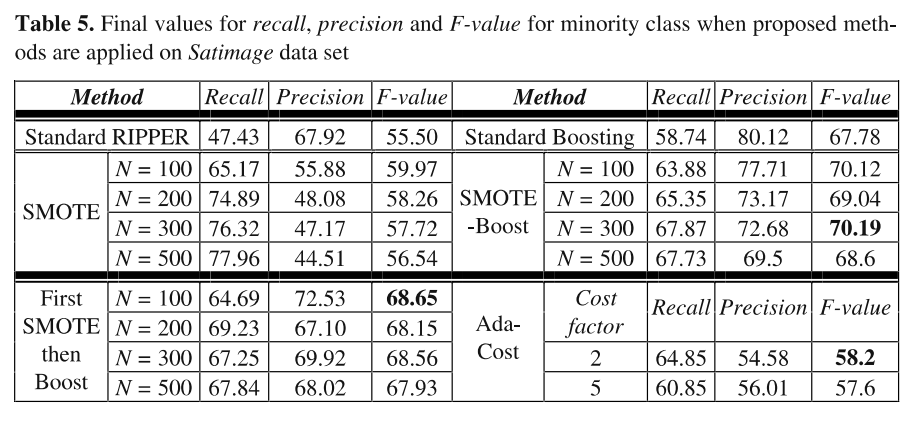
다음은 Satimage 데이터셋을 사용하여 F-value를 보았는데, 이때는 N=300으로 설정했을 때 성능이 가장 좋은 것을 확인할 수 있습니다.
이처럼 SMOTEBoost 모델이 기존의 SMOTE기법보다 성능이 좋은 것을 알 수 있으며 생성하는 숫자는 데이터셋마다 다른 것 같습니다.
확실히 SMOTE 기법만 사용하는 것보단 Boosting 모델을 결합하여 쓰면 성능이 좋은것을 알 수 있습니다.(아마도 부스팅의 목적이 오분류된 데이터를 더 잘 분류할 수 있도록 하는것이 목적이니까 소수 클래스를 잘 분류하는 모델을 만들어야하는 목적과 부합해서 좋은 시너지를 낼 수 있는 것 같습니다!)
이번 게시글에서는 2022년에 IEEE에 발표된 Learning From Imbalanced Data With Deep Density Hybrid Sampling 논문을 다뤄보겠습니다.
Abstract
Imbalaced data 문제를 해결하기 위해서 많은 방법들이 있었는데, 대부분의 방법들은 오직 minority, majority class에 대해서만 고려하고 그 두개의 클래스 간의 관계에 대해서는 고려하지 않고 있습니다.
게다가 데이터 생성하는 많은 방법들이 original feaure space로부터 데이터를 생성하고 있으며 이때 Euclidean distance를 사용합니다(SMOTE처럼). 하지만, high dimensional space일수록 Euclidean distance는 더이상 중요한 거리가 되지 않습니다. 그래서 저자는 새로운 방법론인 DDHS(deep density hybrid sampling)방법을 소개하며 불균형 문제를 해결하고자 합니다.
저자가 기존의 방법론들과 어떻게 다르게 접근하여 불균형 문제를 해결했는지 살펴보도록 하겠습니다.
Proposed Method
많은 Data-level 방법들이 SMOTE를 응용한 방법이지만, 크게 2가지 문제를 가져온다고 합니다.
오직 MInority samples만 고려하고, Majority class가 가져오는 영향을 무시한다
Nearest neighbors를 찾기 위해 Euclidean distance(SMOTE에선 이 거리를 사용함)를 사용하지만, high-dimensional datasets에서는 정확하게 측정할 수 없다.
이 문제를 해결하기 위해 저자는 어떻게 해결하려고 했는지 살펴보겠습니다.
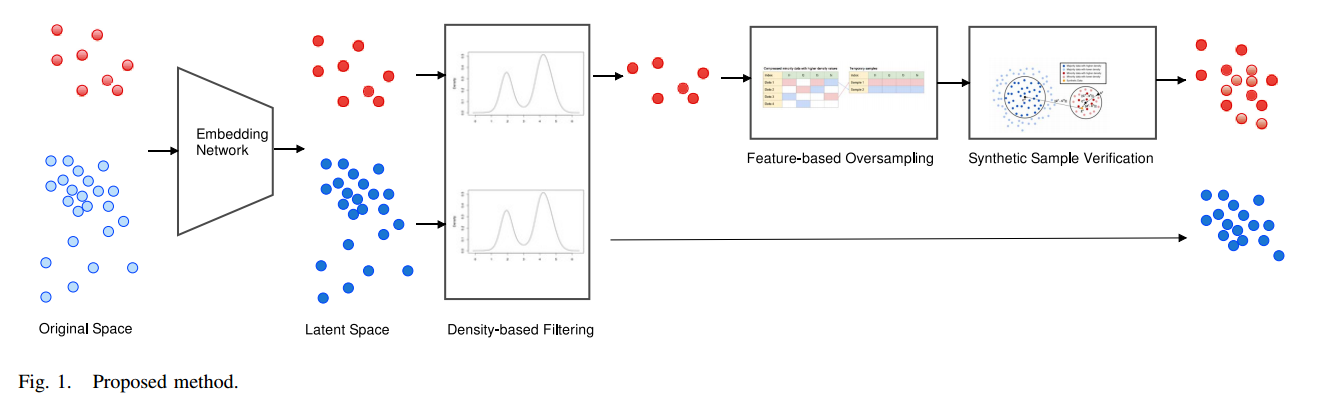
위 사진은 저자가 제안한 모델의 아키텍쳐입니다. 이 부분을 하나하나씩 살펴보도록 해서 어떻게 Oversampling, Undersamplilng을 수행했는지 확인해보도록 하겠습니다.
Notation
위 과정을 진행하기 전에 Notation에 대해 정의하고 수행하겠습니다.
$\{(x_i,y_i)^m_{i=1}\}, where \ x_i \in \mathbb{R}^D$
$x_i$ : feature vector
$y_i$ : corresponding label
$m$ : the number of training examples
$z_i$ : $x_i$에 의해 projection된 벡터 $z_i \in \mathbb{R}^d$
이때 d<D ($x_i$를 저차원 $z_i$로 사영시켰으므로 D가 d보다 큰것은 자명합니다.)
이 작업은 binary classification 작업에 초점이 맞춰져 있습니다.
Embedding Network
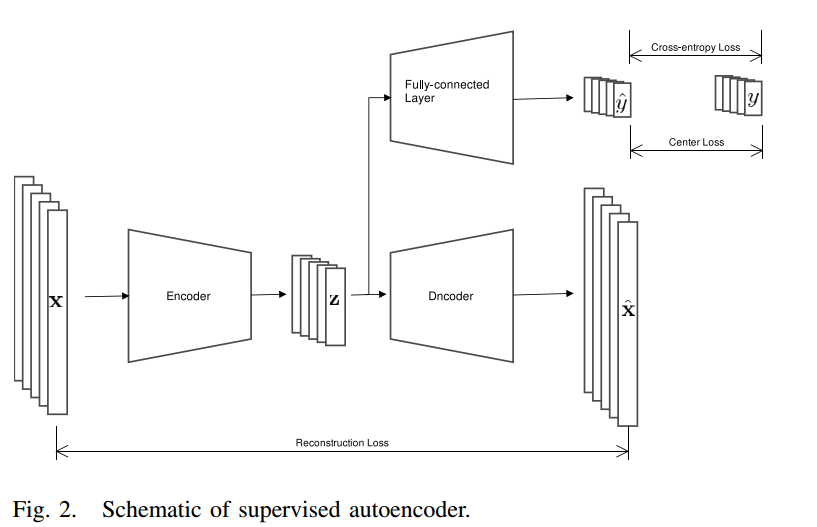
저자는 제안된 방법을 develop하기 위해 autoencoder를 활용하였습니다.
Original autoencoder의 구조는
Encoder
원본 데이터를 latent space으로 변환시키는 네트워크
Decoder
latent vector들을 원본 데이터로 복원하는 네트워크
이렇게 2가지로 구성되어있습니다.
목표는 reconstruction loss를 최소화함으로써 Encoder와 Decoder를 동시에 최적화 하는 것입니다.
$x$ : 원본데이터
$D(E(x))$ : 원본데이터를 Encdoer를 통해 latent space로 축소시키고 다시 디코더를 통해 원본데이터의 차원으로 복원한 데이터
지도학습의 경우, 훈련 과정에서 레이블 정보를 활용하면 예측 성능을 향상시킬 수 있습니다. 이는 모델이 class 근접성을 유지하면서 동일한 클래스의 샘플들이 잠재 공간에서 더 가까워지도록 학습하는 데 도움이 됩니다. 따라서, 저자는 총 3가지 손실 함수를 사용하여 이러한 효과적인 학습을 달성하려고 합니다.
아래 그림은 저자가 제안한 방법의 아키텍쳐입니다.
3가지 손실함수는 다음과 같습니다.
1. Reconsturction loss
Autoencoder에 의해 계산이 되고, 이때 MSE(mean square error)를 사용하여 loss를 계산하게 됩니다.
$x_i$ : original data point(원본 데이터)
$\hat{x_i}$ : reconstructed data point(복원된 데이터)
$b$ : batch size(배치 사이즈)
실제 데이터와 Encoder, Decoder를 거쳐서 복원된 데이터간의 차이가 어느정도인지 MSE를 통해 계산되어 이 loss가 최소가 되도록 업데이트 됩니다.
2. Cross-entropy loss
또한 저자는 Cross-entropy loss를 제안했는데, 레이블 정보를 활용하여 클래스가 다른 데이터들간의 거리는 멀게, 클래스가 같은 데이터들간의 거리는 가깝게 하는것이 목적입니다!
이렇게 loss를 설정함으로써 부정확한 클래스로 분류된 데이터에 대해서 패널티를 부과하여 loss를 계산하게 됩니다.
3. Center loss
마지막 손실함수는 Center loss함수입니다. 말 그래도 Class Center로부터 멀어질수록 패널티를 부여하게 됩니다. 그래서 이 loss를 통해서 같은 클래스들끼리 center로 향하도록 하는것이 목적입니다.
$c_{y_i}$ : latent space에서 $y_i$클래스의 center
$z_i$ : latent vector
이 3가지 loss 함수를 통해서 projected data point들이 latent space에서 separable하게 하는 것이 목적입니다. latent space는 original feature space보다 저차원이기 때문에 high dimensional space에의해 발생되는 문제를 완화할 수 있습니다.
최종 loss는 다음과 같습니다.
Density-Based Filtering
Embedding network훈련 과정이 완료된 후 저자는 high-quality datapoint를 선택하기 위한 기준으로써 density를 사용합니다.
Low-density data들은 다른 data point들과 멀이 떨어져 있기 때문에 noise가 될 수 있고,
High-density data들은 cluster를 대표할 가능성이 큽니다.
저자는 이 part에서 high-density에 존재하는 data point에 대해 정의하고자 합니다.(어떤 기준으로 data가 high, low density에 속하는지)
저자는 latent space에서 데이터들의 density를 추정하기 위해 KDE(Kernel Density function)을 사용합니다. 그 중 Gaussian kernel을 사용하여 density를 추정하고자 합니다.
아래 링크는 kernel density function에 대해서 자세하게 다뤄주신 블로그 글입니다. 자세하게 설명해주셔서 궁금하신 분들은 확인해보시길 바랍니다!
이제 density를 majority, minority class에 대해서 추정하려 합니다.
Majority class
majority density $Q_2$의 quartile보다 큰 data들만 유지시키도록 합니다.
Minority class
minority density $Q_3$의 quartile보다 큰 data들만 유지시키도록 합니다.
훈련 과정에서 데이터의 25%만을 유지하며 oversampling을 수행하지만, 나머지 75%의 데이터를 완전히 버리는 것은 아닙니다. 이 데이터는 나중에 classifier 훈련 과정에 포함될 예정이며, 특히 majority 데이터의 50%는 undersampling 과정에서 삭제됩니다.
이런 이유때문에 hybrid sampling인 것 같네요.
Generation of Synthetic Samples
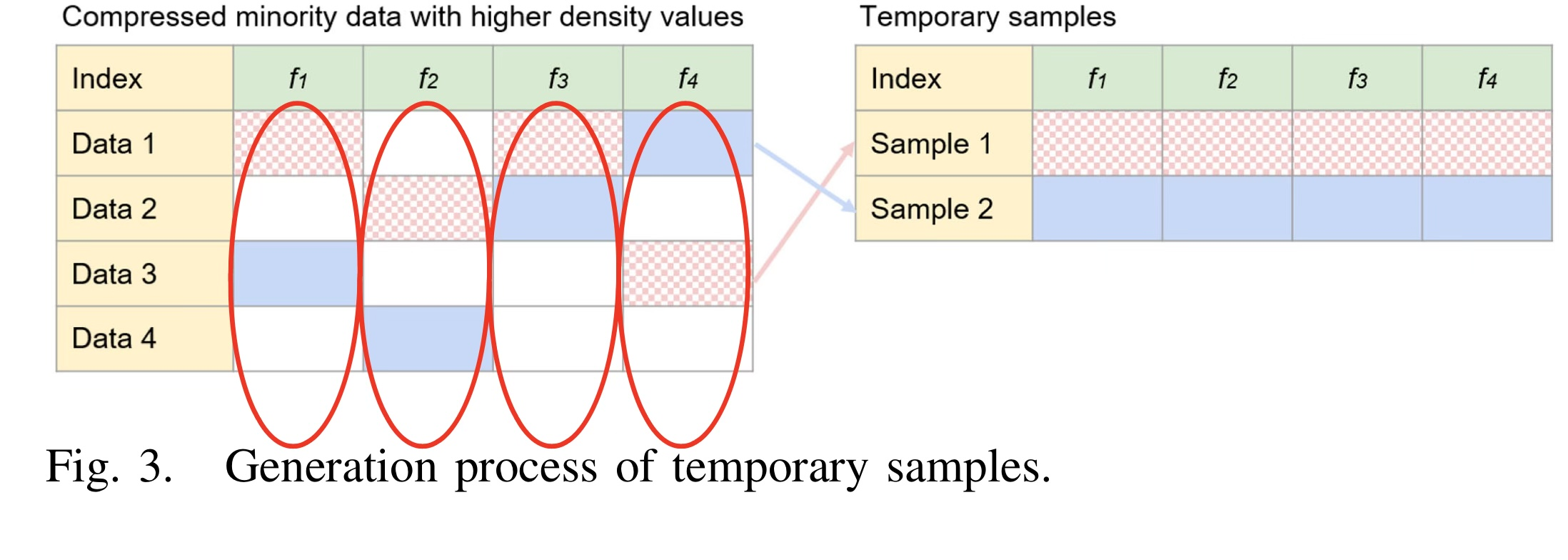
위 그림은 데이터 생성하는 방법입니다. Minority class를 oversampling 하는 법에 대해 설명하도록 하겠습니다.
아래 그림은 4개의 latent vector가 존재하고, 4개의 DATA가 존재한다고 가정하고 있습니다.
저자는 다양한 synthetic samples를 생성하기 위해 feature-level sampling 기법을 제안합니다.
위 그림을 예시로 들어서 설명하겠습니다. (latent feature은 4개)
Minority class에서 선택된 샘플들의 latent feature 집합 $V=[v_1,v_2,...,v_4]$이 주어지면, 각 feature의 value set이 정의됩니다.
먼저, 첫 번째 latent feature $v_1=[v_{11},v_{21},...,v_{41}]$(빨간색 원)에서 하나의 값을 무작위로 선택(복원 추출)하여 synthetic sample을 생성하기 시작합니다.
동일한 방식으로 나머지 feature2,3,4 들도 순차적으로 선택해 synthetic sample을 생성합니다.
랜덤한 process로 진행되기 때문에 생성되는 samples의 다양성을 높일 수 있습니다.
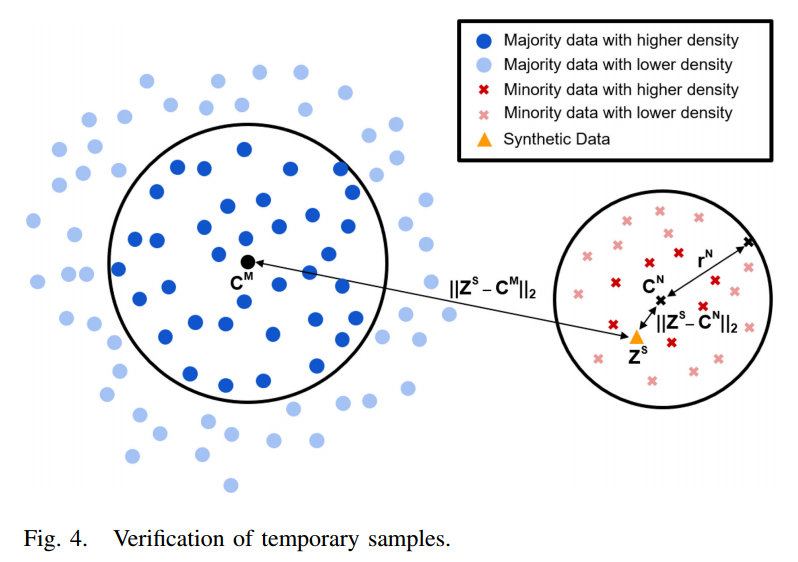
Verification of Synthetic Samples
Generation process가 완료되면, 생성된 샘플들이 좋은 퀄리티를 가지고 있는지 평가해볼 필요가 있습니다.
좋은 데이터가 생성됐는지에 대한 평가 기준은 density를 사용하게됩니다.
아래 사진은 각각에 대한 Notation입니다.
그리고 아래 사진에는 좋은 데이터가 생성됐는지에 대한 기준입니다.
위의 식을 보면 생성된 데이터가 Majority class의 center보다 Minority class의 center보다 가까운지 확인하는 것입니다. 즉, Minority class의 데이터를 oversampling 했으니 생성된 데이터는 Minority class의 center보다 가까워야겠죠? 그래서 저 조건이 성립해야 합니다.
또한 두번째 식을 보면 생성된 샘플과 Minority class의 거리가 center Minority class의 반지름보다 작아야 합니다. 조금 더 high-quality를 가진 샘플이 생성되어야한다는 조건을 추가로 만든 것 같습니다.
이렇게 두가지 식의 조건을 만족하면 좋은 퀄리티를 가진 데이터가 생성되었다고 볼 수 있습니다.(근데 사실 2번째 식만 만족하면, 첫번째 식은 자동으로 만족되는 것 같은데 굳이 첫번째 식이 필요한가?라고 생각해봤습니다….)
Experimental Results
저자가 데안한 모델을 다른 Data-level algorithm과 비교해서 성능이 어떤지 확인해보겠습니다.
Linear SVM을 사용하여 AUC와 AUPRC를 측정하였습니다.
AUC
AUPRC
저자가 제안한 모델이 대체적으로 좋은 성능을 가지는 것을 확인할 수 있습니다.
또한 Embedding Network에서 사용된 Loss functino에 대해서 Ablation studies를 진행한 결과입니다.
역시 3가지 loss를 사용하면 좋은 성능이 나타나는걸 확인할 수 있습니다
cross-entropy loss가 분류기가 제대로 분류하면 loss가 작아지고, 못하면 loss가 커지기 때문에 만약 binary classification 에서 분류기가 분류를 더 잘한다면 더 좋은 성능을 가질 수 있지 않을까?라는 생각이 듭니다!
이번 글에서는 latent space에서 Minority class를 oversampling하여 불균형 문제를 해결할 수 있는 논문을 다뤄보겠습니다.
Abstract
이 논문은 데이터 불균형의 문제를 해결하기 위해 Minority class의 데이터를 latent space에서 Oversampling하여 불균형 문제를 해결하고자 합니다. 이때 Minority class의 데이터는 RAE(Regularized Auto Encoder)를 통해 latent space로 보내지게 됩니다.
latent space에서 Oversampling을 수행하기 때문에 좋은 latent space(데이터를 잘 표현해주는 잠재 공간)를 학습해야 합니다. 그러기 위해서 저자는 Auto-Encoder의 구조를 사용해 조건부 데이터 우도(conditional data likelihood)를 최대화함으로써 latent space를 효과적으로 학습합니다. (특히, latent 샘플들의 convex combination을 사용해 새로운 데이터를 생성하면서도 동일한 클래스의 identity를 보존해야 한다고 합니다. 즉, convex combination을 통해 생성된 데이터가 같은 클래스를 가져야 한다는 뜻 )
또한 저자는 SMOTE와 같은 naive한 oversampling방법과 비교하여 low variance risk estimate을 달성했다고 합니다. 결과적으로 이 방법은 Minority class를 oversampling하는데 효과적이며 불균형 데이터를 해결하는데 도움을 준다고 합니다.
이제부터 차근차근 하나씩 살펴보도록 하겠습니다.
Proposed Method
Class Preserving Oversampling
여기서는 latent space의 분포인 q(z)가 클래스 보존 방식으로 학습되는 것이 핵심입니다.
이때 latent space에서 convex combination을 통해 새로운 샘플을 생성하고자 합니다.
예를 들어 $z_i, i=1,2,...,t$ 이때 $z_i$는 latent vector라고 하고 그에 상응하는 데이터포인트 $x_i, i=1,2,...,t$가 모두 같은 클래스를 갖고있다고 하면 이때 새로운 latent point $z'$은 다음과 같이 얻어집니다.
하지만, 단순히 이렇게 convex combination을 통해 생성된 새로운 데이터는 클래스 보존을 하지 못할수도 있습니다. (각 클래스의 latent space가 겹치는 영역이 존재하게 되면 convex combination을 통해서 생성된 데이터가 클래스 보존을 못할수도 있다는 얘기인 듯 합니다.)
그래서 클래스 보존에 대한 문제를 해결하기 위해서는 두가지를 말하고 있습니다.
class-conditional latent space를 학습해야 합니다.이때 각 클래스별로 class-conditional latent density가 겹치지 않아야 한다고 합니다. 즉,각 클래스마다 서로 다른 영역을 가진 latent space를 가져야 합니다.
각 클래스들은 latent space에서 linearly separable해야 됩니다.
각 클래스 i에 속하는 샘플들의 집합 $R_i=\{x|h(z)=i\}$는, linear classifier h(z)에 의해 클래스 레이블 i를 갖는 샘플들입니다. 이때 $q(z|x\in R_i)$는 클래스 i에 대한latent 분포를 의미합니다. 그리고 두 클래스 i, j에 대한 latent 분포의 support가 겹치지 않도록 학습해야 합니다.
즉, $Supp(q(z|x\in R_i)) \cap Supp(q(z|x\in R_j)) =\varnothing$식을 만족해야 합니다.latent space 학습과 linear classifier 학습을 함께 진행하여 oversampling된 벡터도 원래 클래스에 속하도록 만드는 방식을 다루고 있습니다.
위 두가지인 latent space 학습과linear classifier 학습을 함께 진행하여 oversampling된 벡터도 원래 클래스에 속하도록 만드는 방식을 다루고 있습니다.
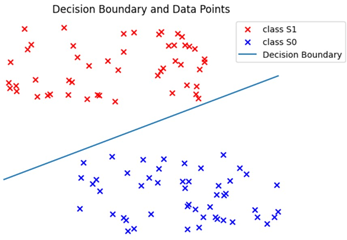
여기서 linear classifier는 latent space에서 벡터들이 같은 클래스에 속하는지 확인하는 역할입니다. 예를 들어, 클래스 S1에 속하는 여러 샘플의 latent 벡터를 결합했을 때, 새로운 벡터도클래스 S1로 분류되도록linear classifier가 학습됩니다.(위 사진처럼 linear classifier가 linearly separable하다면 S1의 latent vector들의 convex combination도 S1의 Decision Boundary에 속할 것이라는 겁니다.)
위 사진을 보면1. class-conditional latent space를 학습하였고(겹치지 않는 latent space), 2. latent space에서 linearly separable함!(저런 상태를 원함)
Regularized Autoencoders with class preserving latent space
이 부분은클래스 정보를 유지하면서 오버샘플링을 수행하기 위한latent space 학습 방법을 설명합니다. 저자는degenerate representation을 방지하기 위해클래스 보존 제약을 적용하여 **조건부 데이터 우도(conditional data likelihood)**를 최대화하면서latent space를 학습합니다.
이를 위해Regularized Auto-Encoder구조를 활용하여 클래스 정보를 보존한 채latent space를 학습합니다.
Degenerate Representation이란?
Degenerate representation이란, 학습된 모델이 입력 데이터를 지나치게 단순화하거나 압축하여중복되거나 정보가 손실된 표현을 만들어내는 상황을 의미합니다.latent space에서 서로 다른 데이터들이 거의 동일한 벡터로 매핑되거나, 각 데이터의 고유한 특성들이 사라져 버리는 것을 말합니다.
만약 단일 latent vector로 매핑이 된다면 (위에서 언급했던Class Preserving Oversampling) latent space가 클래스를 보존할 수는 있겠지만, 다양한 데이터를 생성할 수 없게되어oversampling의 의미가 없어진다고 볼 수 있습니다.
이 문제를 해결하기 위해서 $p(x|z')$(conditional data-likelihood)를 최대화 하여 latent space를 학습한다고 합니다. 이때 클래스 보존 제약을 추가하여각 클래스 간의 latent space가 겹치지 않아야 합니다!
Encoder-Decoder 구조
Encoder: 입력 데이터(x)를latent space로 축소합니다. 이때 조건부 잠재 분포(conditional latent distribution)를 학습하여, 입력 데이터가 어떤 클래스에 속하는지 반영한 채로 latent 벡터 z로 변환합니다. 이는 $q_\varphi(z|x)$로 표현됩니다. ( $\varphi$는 parameter)
Decoder: 학습된 latent 벡터 $z'$(이 $z'$은 latent vector들 간의 convex combination)를 기반으로, 원래 데이터를 복원하는 네트워크입니다. 이는 $p_\theta(x|z')$로 표현되며, oversampled된 데이터가 복원될 때도 클래스 정보가 잘 유지될 수 있도록 학습됩니다.
조건부 데이터 우도(Conditional Data Likelihood)
Decoder네트워크에서 Conditional Data Likelihood( $p(x|z')$ )를 최대화하여, latent space에서 학습된 데이터가 원본 데이터를 잘 복원할 수 있도록 합니다. 이 과정을 통해 latent space가 데이터를 잘 표현할 수 있는 구조로 학습됩니다.
여기서 클래스 보존 제약으로 linear classifier인 $h_w(z)$를 사용합니다. 이 linear classifier는 latent space에서 클래스 간 겹침이 없도록 학습합니다.
이제 최적화 문제를 해결하는데클래스 보존을 유지하면서latent space를 학습하고자 합니다!
conditional data likelihood를 최대화 하여 latent space에서 얻어진 벡터 z가 degenerate representation을 피하면서 원본 데이터를 잘 표현하도록 합니다.이때 제약조건으로 latent space에서 각 클래스간 겹침이 발생하지 않아야 합니다. ($Supp(q(z|x\in R_i)) \cap Supp(q(z|x\in R_j)) =\varnothing$)
conditional data likelihood를 최대화 하여 latent space에서 얻어진 벡터 z가 degenerate representation을 피하면서 원본 데이터를 잘 표현하도록 합니다.이때 제약조건으로 latent space에서 각 클래스간 겹침이 발생하지 않아야 합니다. ($Supp(q(z|x\in R_i)) \cap Supp(q(z|x\in R_j)) =\varnothing$)
세가지 네트워크인 Encoder, Decoder, Classifier는 동시에 학습됩니다. 학습과정에서 convex combination을 통해 oversampling이 진행되게 됩니다. 학습이 완료되면 oversampling된 데이터의 클래스를 보존할 수 있게 되며 성능이 향상될 것입니다.
Implementation Details
제안된 모델은 Encoder network($E_\varphi$), Decoder network($D_\theta$), 그리고 latent space는 linear classifier($L_\omega$)로 구성되어있습니다. (이때 linear classifier는 선형적으로 클래스들을 분리할 수 있도록 제약 걸었음)
이제 저자가 제안한 모델의 아키텍처를 살펴보겠습니다.
Figure 1: Architecture of the proposed methodology. It is a regularized autoencoder, where thelatent space is regularized using a linear classifierto facilitate distance metric free class preserving oversampling of the minority classes. The decoder network maximizes the conditional data likelihood to avoid degeneracy in the latent space.
Mixer Network
위 그림을 보시면 $M_\xi$가 존재하는데 이는Mixer network라고 불리며 여러 latent vector $z_i$들을 입력으로 받아 oversampling을 위한 mixing coefficient $\alpha$를 생성합니다. Mixer network는softmax 층을 통해$\alpha$를 생성합니다.
Mixer network는 linear classifier가 분류하기 어려운 샘플을 생성하도록 학습되며 그러기 위해서는 cross-entropy loss를 최소화하도록 학습됩니다. 즉, 새롭게 생성된 $z'$이 linear classifier에 의해 올바르게 분류되지 못하도록 합니다.
Loss는 oversampled된 샘플 $z'$가 원래 $z_i$들과 다른 레이블을 가지도록 설정됩니다. 즉, linear classifier가 이 oversampled된 샘플을 정확하게 분류하지 못하게 하는 것을 목표로 학습됩니다.
아래는 mixer network의 loss입니다.
C : 전체 클래스의 수
$y_j^{(k)}$ : 클래스 j에 대한 one-hot 인코딩된 레이블입니다. 데이터가 클래스 j에 속하면 1, 아니면 0
$\hat{y}'(k)=L_\omega(z')^{(k)}$: linear classifier $L_{\omega}$가 oversampled된 latent vector $z'$에 대해 예측한 클래스 j의 확률입니다.
이 loss function의 목적은 mixer network가 만든 oversampled된 latent vector $z'$이 linear classifier $L_{\omega}$에 의해 잘못 분류되도록 유도하는 것입니다.
cross entropy loss를 최소화한다는 것에 직관적으로 이해가 되지 않을 수 있어 예를 들어 설명하겠습니다.
Class : 개, 고양이, 토끼 이렇게 3개의 클래스가 있다고 하겠습니다.
원래 클래스는 개라고 설정하겠습니다.(i=개) 그리고 개의 latent vector들의 convex combination으로 새롭게 생성된 $z'$은 개이지만, 임의로 고양이로 설정하겠습니다.(j=고양이)
그러면 분류기는 $z'$에 대해 당연히 개라고 분류할 확률이 높겠죠? (개의 latent vector들로 convex combination을 수행했으므로!)
loss는 0.7985가 되었습니다. 즉, cross entropy를 최소화 하려면 분류기가 고양이의 확률을 높이는 것입니다. 결국 $z'$에 대해서 분류기는 개와 고양이 중에 분류하기 어려운 샘플이 만들어 지겠죠? 그것이 이 Mixer network가 원하는 것입니다!(분류기가 분류하는데 어려움을 겪게되는 샘플을 생성하는 것)
$z'$은 강아지 label을 갖지만, 고양이와 강아지를 확실하게 분류하기 어려운 샘플을 만드는 것이지요!
이를 통해, Mixer 네트워크는challenging samples를 생성하여 모델의robustness를 향상시키고, latent space에서 클래스 보존과 다양성을 동시에 유지하게 됩니다. (Mixer network의 역할은 $\alpha$를 다양하게 설정하여 동일 클래스 내에서 다양한 샘플을 생성하는 것입니다. 논문에서 각 클래스 간의 latent space가 겹치지 않도록 설계되었기 때문에, $\alpha$를 통해 어려운 샘플을 만들어도 클래스는 변하지 않습니다. 따라서, Mixer network는 클래스 내에서의 데이터 다양성을 높이기 위한 과정으로 이해할 수 있을 것 같습니다!)
이제 Mixer network를 살펴보았으니 Encoder, Decoder, linear classifier부분의 loss를 살펴보겠습니다.
Decoder
Decoder부분에서는 $p_\theta(x|z')$를 최대화 합니다. 저자는 adversarial loss를 사용하여 decoder가 생성한 데이터의 분포와 기존의 데이터의 분포를 일치시키기 위함입니다. 여기서 WGAN-GP를 사용하여 안정적이고 수렴이 잘 되도록 합니다. 또한 Critic network를 도입하는데, 이는 생성된 샘플과 실제 데이터 샘플 간의 차이를 줄이고, 그래디언트 패널티를 통해 안정적인 학습을 보장합니다!
(아마 여기서 WGAN-GP를 사용한 이유는 만약 분포끼리의 겹침이 없으면Kullback-Leibler Divergence & Jensen-Shannon Divergence는 안정적으로 학습이 어려워 wasserstein distance를 사용해 분포간 거리를 일치시키는 것 같습니다.)
Decoder 손실함수
의미: 디코더는 Critic 네트워크의 출력을 최대화하여, 생성된 샘플이 실제 데이터와 유사한 분포를 갖도록 유도합니다.
Critic 손실함수
의미: Critic은 생성된 샘플과 실제 데이터 샘플 간의 차이를 줄이고, 그래디언트 패널티를 통해 안정적인 학습을 보장합니다.
디코더 단독으로는 생성된 샘플이 실제 데이터 분포와얼마나 유사한지를 직접적으로 측정하기 어렵습니다. 단순한 재구성 손실(reconstruction loss)이나 픽셀 단위의 손실은 샘플의 질적 유사성을 제대로 반영하지 못할 수 있습니다.
Critic network는 생성된 샘플과 실제 샘플 간의 분포적 차이를 측정하여, Decoder가 보다 정교하게 학습할 수 있도록 피드백을 제공합니다.
그리고 여기서 sample-by-sample 간의 매치가 아니라 하는데, 그 이유는 생성된 데이터는 기존의 데이터에 존재하지 않기때문에 샘플들 간의 매치를 보는것이 아닌 생성된 데이터의 분포와 기존의 데이터의 분포 차이를 보는거라고 하고 있습니다.
Linear Classifier
다음은 linear Classifier에 대해서 설명하겠습니다.
여기서는 categorical crossentropy loss terms을 사용하게 되는데, 이때 사용되는 데이터는 (i=개의 개수와 새롭게 생성된 $z'$까지 총 t+1개의 데이터에 대해서 loss를 구하게 됩니다.)
아래는 classifier에 대한 loss function입니다.
여기서 $z'$ 외에는 앞에 텀에서 계산이 되고, 뒤에 텀에서 $z'$에 대한 loss가 계산이 되는데, 이번에는 분류기가 $z'$에 대해서 강아지로 분류할 수 있도록 업데이트 됩니다.(앞에서는 일부러 $z'$을 고양이로 설정해서 $\alpha$를 만들었지만, 얘는 결국엔 강아지에 대한 데이터입니다. 그렇기 때문에 여기 linear classifier에서는 $z'$에 대해서 강아지라고 제대로 분류할 수 있도록 손실함수를 업데이트 해야합니다!)
Encoder
Encoder network에서 input data를 latent space로 보낼때 중요한 정보를 담고잇도록 해야합니다.
아래는 encoder에 대한 loss function입니다.
encoder손실에는분류 손실과,평균 절대 오차 손실로 구성되어있습니다.
분류 손실을 학습하여 latent space에서의 vector들이 중요한 정보를 담을 수 있도록 합니다.
평균 절대 오차 손실에서는 input data랑 input data를 Encoder를 통해 잠재벡터로 변환 후 다시 디코더를 통해 복원한 데이터 간의 차이를 확인해 재구성이 잘 되도록 합니다. (또한 재구성이 잘 됐다는건, latent space에서 latent vector가 중요한 정보를 담고있었다고 해석할 수 있습니다.)
Experimental Results
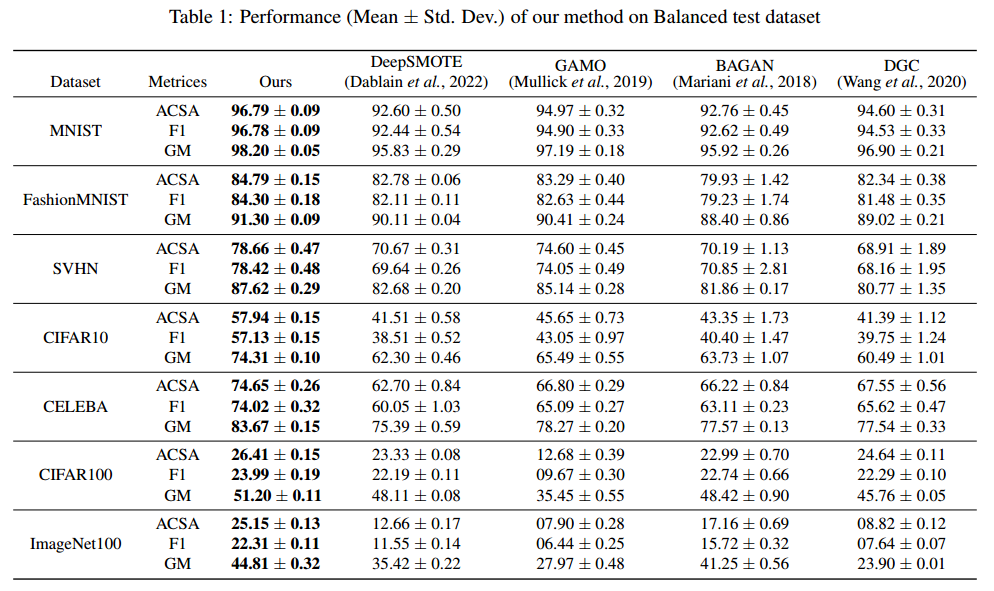
제안한 모델이 다른 모델에 비해 성능이 얼마나 좋은지 확인해보도록 하겠습니다. 다양한 Vision data를 사용하고, 성능평가 지표로는 ACSA, F1 score, GM 을 사용하였습니다.
저자가 제안한 모델이 확실히 성능이 좋은 것을 알 수 있습니다!
또한 데이터의 질적 및 다양성을 측정하기 위한 지표로 Density와 Coverage를 사용했습니다. 이 지표들은 생성된 샘플이 실제 데이터 분포를 얼마나 잘 반영하고 있는지, 그리고 얼마나 다양한 샘플을 생성하고 있는지를 평가하는 데 유용합니다.
높은 Density 값은 생성된 샘플이 실제 데이터의 특정 영역에 집중적으로 분포되어 있음을 의미하며, 이는고품질의 샘플이 생성되고 있음을 시사합니다.
높은 Coverage 값은 생성된 샘플이 실제 데이터의 다양한 특성을 잘 반영하고 있음을 의미하며, 이는다양한 샘플이 생성되고 있음을 시사합니다.
확실히 제안된 모델이 전체적으로 다양한 데이터를 생성하고 있으며 실제 데이터 영역에 집중적으로 분포되어 있음을 알 수 있습니다!
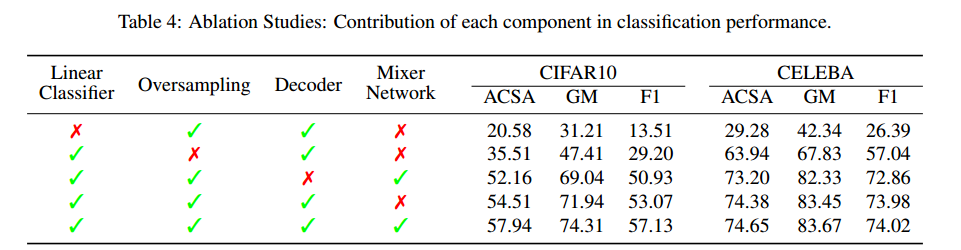
그리고 또한 Ablation studies를 통해 어떤 process에서 성능이 효과적이었던지도 파악할 수 있습니다.
Mixer Network를 사용한 모델과 사용하지 않은 모델에 대해서는 그다지 큰 차이가 나타나지 않았네요. (되게 신박한 아이디어라고 생각했는데, 성능 측면에서는 엄청난 효과를 불러일으키진 않았네요)
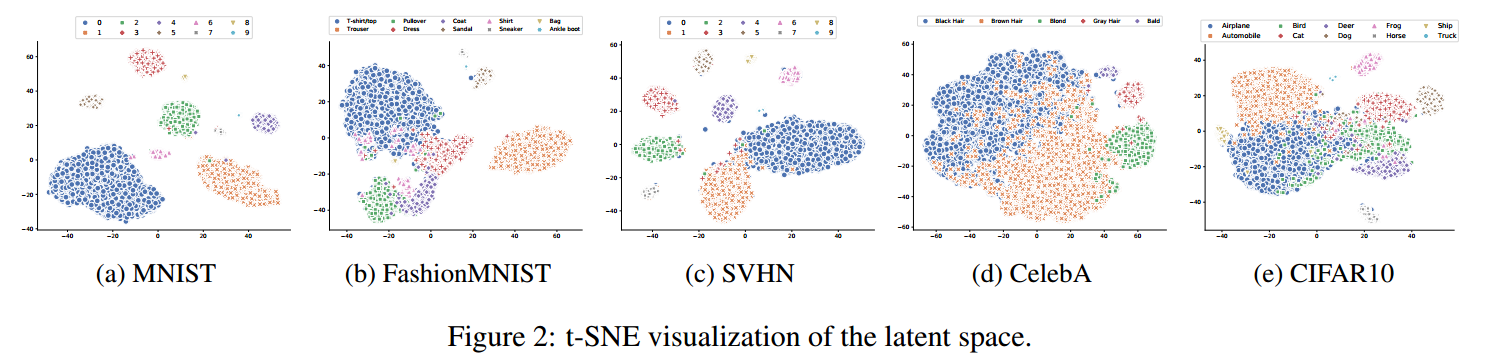
마지막으로 위 사진은 latent space에서 각 클래스의 분포를 나타낸 것인데, MNIST의 데이터 경우에는 확연하게 분리가 되어져 있는 것을 볼 수 있습니다.(degenerate representation을 방지하기 위해 class-preserving regularization을 추가해 각 클래스들간 latent space에서 겹침이 없어야 한다는 조건을 어느정도 만족시킨 것 같습니다.) (다른 data의 경우에는 linearly separable하진 않게 나오긴 했네요. 완벽하게 linearly separable 하다면 엄청난 모델이 될 것 같습니다!)
Conclusion
Minority class의 데이터를 oversampling하는데 클래스 보존의 제약을 걸어주고 다양한 데이터를 생성할 수 있게 하였습니다. Imbalanced data의 상황에서 이 모델은 아주 강력한 무기가 될 것 같습니다. 이런 concept을 vision data 뿐만 아니라 Tabular data에 대해서도 적용할 수 있으면 좋은 모델이 생길 수 있지 않을까 생각해 봅니다. Tabular data에 한번 적용시킬 수 있는 Idea를 고려해봐도 좋은 작업이 될 것 같습니다.
이번 글에서는 Oversampling기법과 Undersampling기법에 대해 다뤄보겠습니다.
Imbalanced data
이 게시글에선 Imbalaced data 상황에서 해결할 수 있는 Oversampling과 Undersampling의 개념에 대해서 다뤄보겠습니다.
우선, Oversampling과 Undersampling 기법이 왜 필요한지부터 생각해 볼 필요가 있습니다.
Classfication문제에서 majority class(다수 클래스) data가 minority class(소수 클래스) data의 수보다 훨씬 많은 경우, 모델은 new data(minority class data)에 대해서 주로 majority로 분류하게 되는 경향이 있습니다. 이렇게 되는 경우는 모델이 정확도를 최대화하려고 할 때 발생하게 됩니다.
아래 예시를 들어보겠습니다. 아래와 같이 불량 정상을 예측하는 모델이 있다고 가정하겠습니다.
예측
실제
불량
정상
불량
1
9
정상
11
979
위 표를 보면 이 모델의 정확도는 $\frac{1+979}{1+11+9+979}=\frac{980}{1000}$=0.98입니다. 이 모델은 좋은 모델이라고 할 수 있을까요? 사실 이 모델은 정확도는 되게 높지만, 좋은 모델이 아니라고 볼 수 있습니다. 만약 minority class의 예측을 중요시하게 되는(예를 들어 암과 정상 데이터) 데이터의 경우에는 전혀 도움이 되지 않는 모델입니다. 그래서 이런 Imbalacend data 문제를 해결하기 위해서 Oversampling과 Undersampling이 필요하게 됩니다. 이제 Oversampling과 Undersampling에 대해서 다뤄보겠습니다.
Oversampling
Oversampling은 minority class(소수 클래스)의 data를 복제하거나 증가시켜 majority class(다수 클래스)와의 균형을 맞추는 방법입니다. 이를 통해 모델이 minority class에 대해 더 나은 성능을 나타낼 수 있도록 합니다. Oversampling 기법은 Minority class의 data의 수가 현저히 적을 때 유용하게 사용될 수 있습니다. (위 방법의 경우에는 Minority class의 data를 무작위로 복제하여 샘플 수를 늘리는 방법)
장점(Pros)
소수 클래스 데이터를 효과적으로 늘려 모델이 소수 클래스에 더 민감하게 반응할 수 있도록 함(모두 다수 클래스로 예측하는 문제를 해결할 수 있음)
구현이 간단하고 빠름
단점(Cons)
데이터를 단순하게 복제하기 때문에 과적합(Overfitting)이 될 수 있음
Undersampling
Undersampling은 majority class(다수 클래스)의 data를 줄여 minority class(소수 클래스)와의 균형을 맞추는 방법입니다. 다수 클래스의 데이터가 많을 때 학습 데이터에서 다수 클래스의 샘플을 무작위로 선택해서 그 수를 줄이는 방법입니다.
장점(Pros)
간단하고 빠르며 데이터 셋의 크기가 줄어들어 학습 시간이 단축됩니다.
단점(Cons)
다수 클래스의 데이터를 랜덤으로 선택하여 개수를 줄였기 때문에 다수 클래스의 정보가 손실될 수 있습니다. 그로 인해 모델 성능도 저하가 될 수 있습니다.(모델이 다수 클래스의 중요한 패턴을 학습하지 못할 수 있음)
데이터가 불균형한 상황에서 데이터를 증강시키거나 줄여서 모델의 성능을 향상시킬 수 있도록 하는 Sampling 기법을 다뤄보았습니다. 이 기법들로 인해 불균형한 상황에서 조금 더 중요한 클래스에 대해서 초점을 맞출 수 있습니다.
Oversampling과 Undersampling에는 다양한 기법이 존재하기 때문에 다른 게시글에서 응용기법을 포스팅하도록 하겠습니다.