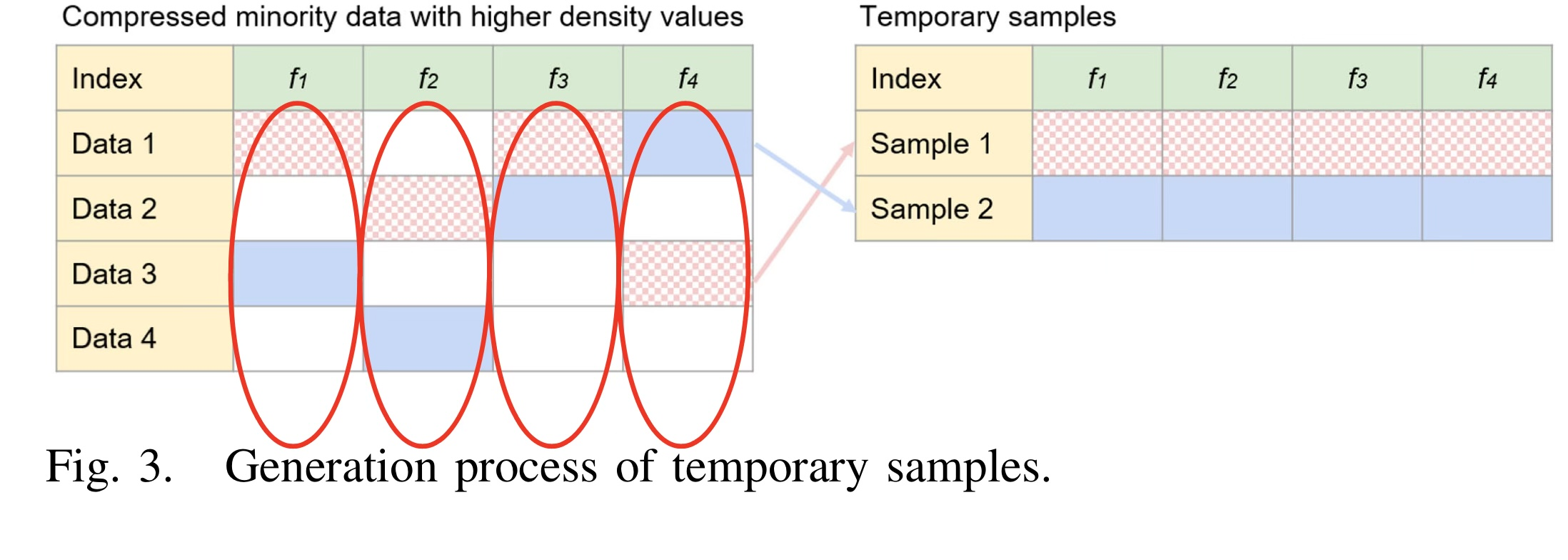
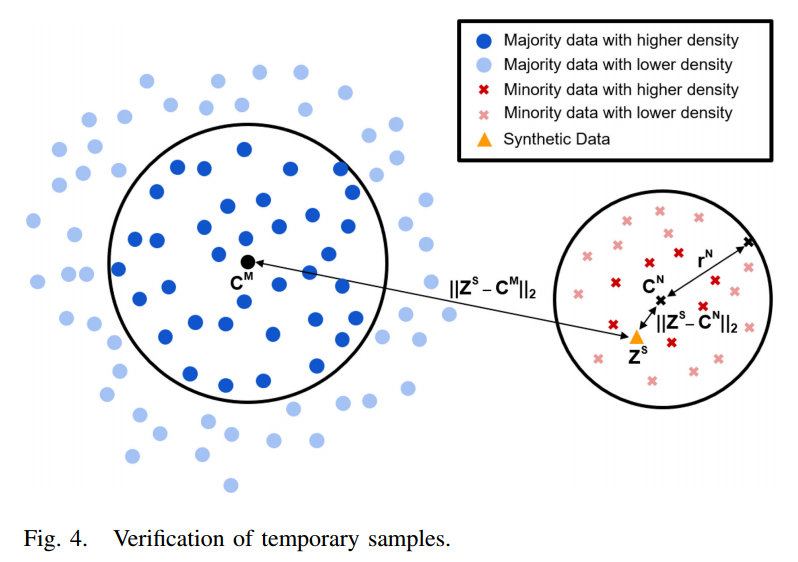
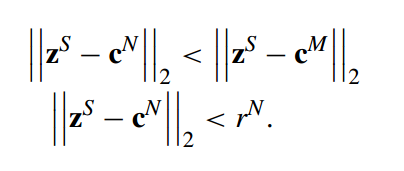이번 글에서는 2023년 5월 International Journal of Machine Learning and Cybernetics 저널에 게재된 OUBoost 논문에 대해 작성하겠습니다.
Abstract
현실 세계에서는 종종 불균형 데이터가 발생하며, 이는 다수 클래스를 잘 예측하지만 소수 클래스에 대해 분류기가 편향되어 예측 정확도가 떨어지는 문제를 야기합니다.
이 논문에서는 Peak clustering 방법을 사용해 다수 클래스의 데이터를 선택하여 undersampling을 수행하는 새로운 기술을 제안합니다. 또한, 소수 클래스에 대해 SMOTE 기반의 synthetic 데이터를 생성하고, 이를 부스팅 알고리즘과 결합한 새로운 OUBoost 알고리즘을 제시했습니다.
30개의 실제 불균형 데이터셋에 대해 여러 평가 지표를 사용하여 실험을 진행했으며, 대부분의 데이터셋에서 OUBoost를 사용했을 때 소수 클래스의 예측 성능이 개선되는 것을 확인했습니다.
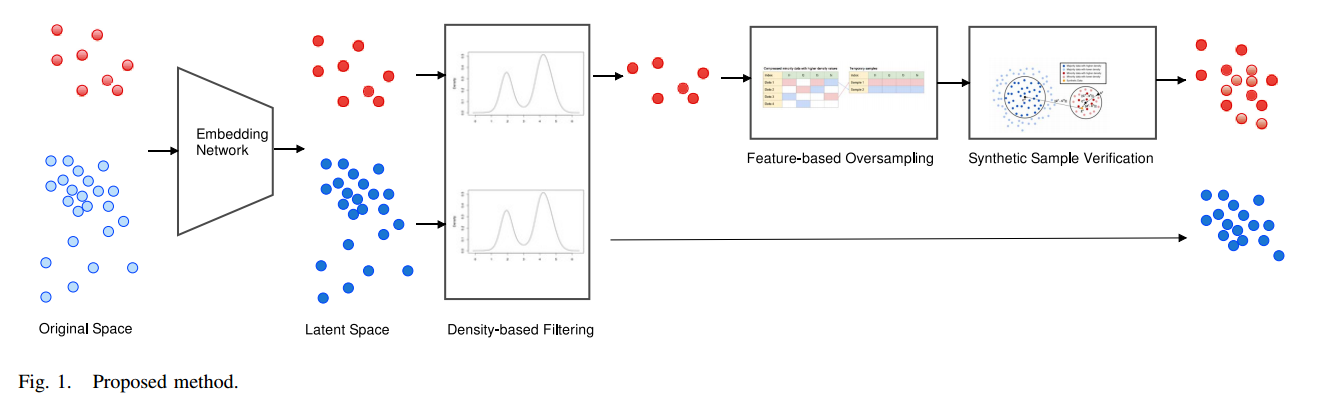
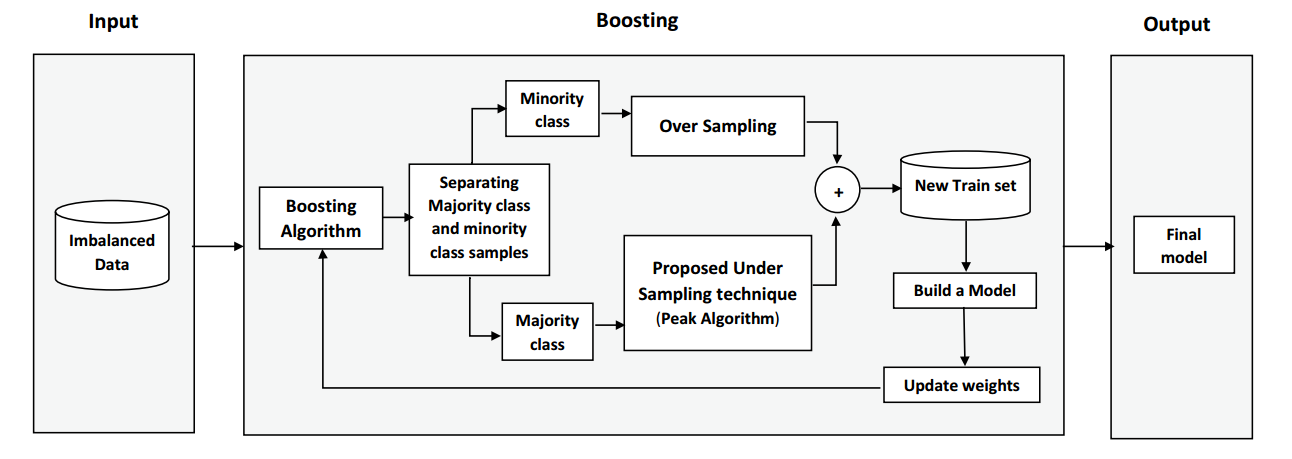
아래 사진은 OUBoost 모델의 아키텍쳐입니다.
Density-peak clustering
이 논문에서 Density-peak clustering(DPC)방법을 사용하여 다수 클래스 데이터를 제거하였는데, DPC가 무엇인지 살펴보겠습니다.
Density-peak clustering (DPC) 알고리즘은 복잡한 구조를 가진 데이터셋에서 클러스터를 식별하기 위해 설계된 클러스터링 알고리즘입니다. 클러스터의 중심을 식별하기 위해 크게 2가지 과정을 거치게 됩니다.
- 클러스터 중심은 local density가 낮은 샘플들 사이에 위치하며, 더 높은 밀도를 가진 샘플들로부터 상대적으로 멀리 떨어져 있습니다.
- 샘플 간의 거리와 local density를 결합하여 클러스터를 정의합니다.
여기서 local density, distance라는 2가지 지표가 클러스터를 정의하는데 사용되기 때문에 각각의 정의들을 살펴보겠습니다.
local density($\eta_i$) : 샘플 j주변에 있는 샘플의 개수를 나타냅니다. 이는 반경 $t_r$ 내에 있는 이웃 샘플 수로 정의됩니다.
$\eta_j = \sum_{k \in S, k \neq j} \Omega(d(j, k) - t_r),$
$d(j,k)$ : 샘플 j와 k간의 거리
$t_r$ : 샘플 주변의 밀도를 결정하기 위한 임계값
$\Omega(y) =\begin{cases}1, & \text{if } y < 0, \\0, & \text{otherwise.}\end{cases}$
만약, 샘플 주변에 데이터가 많으면 $\Omega$값은 음수가 되므로 1을 출력하게 됩니다. 즉, 주변에 데이터가 많을수록 $\eta$값이 커집니다. (보통 클러스터 중심 주변에 데이터가 많이 모이게 되죠! 그러니까 $\eta$가 크다는 건 클러스터의 중심일수도 있다는 것입니다!)
최소 거리($\mu_j$) :더 높은 local density를 가진 샘플들로부터의 최소 거리를 계산합니다. 단, local density가 가장 높은 샘플의 경우, 이는 다른 모든 샘플로부터의 최대 거리로 정의됩니다.
$\mu_j = \begin{cases} \max \{d(j, k) \mid k \in S\}, & \text{if } \eta_j \geq \eta_k \text{ for all } k \in S, \\\min \{d(j, k) \mid \eta_j < \eta_k, k \in S\}, & \text{otherwise}.\end{cases}$
위 과정을 통해 각 데이터 포인트에 대해 $\eta_j$, $\mu_j$를 각각 구하여 클러스터의 중심을 결정합니다.
클러스터 중심
각 샘플의 Density와 Distance를 결합하여 새로운 값 $\lambda_j$를 계산합니다.($\lambda_j=\mu_j*\eta_j$)
$\lambda_j$ 값을 내림차순으로 정렬하고, 높은$\lambda_j$ 값을 가진 샘플을 클러스터 중심으로 선택합니다.
클러스터 할당
클러스터 중심이 결정된 이후, 나머지 샘플들은 가장 가까운 클러스터로 할당되게 됩니다.
$\Psi_j = \begin{cases} j, & \text{if } \eta_j \geq \eta_k \text{ for all } k \in S, \\\arg\min \{d(j, k) \mid \eta_j < \eta_k\}, & \text{otherwise}.\end{cases}$
예를 들어 설명해보겠습니다.
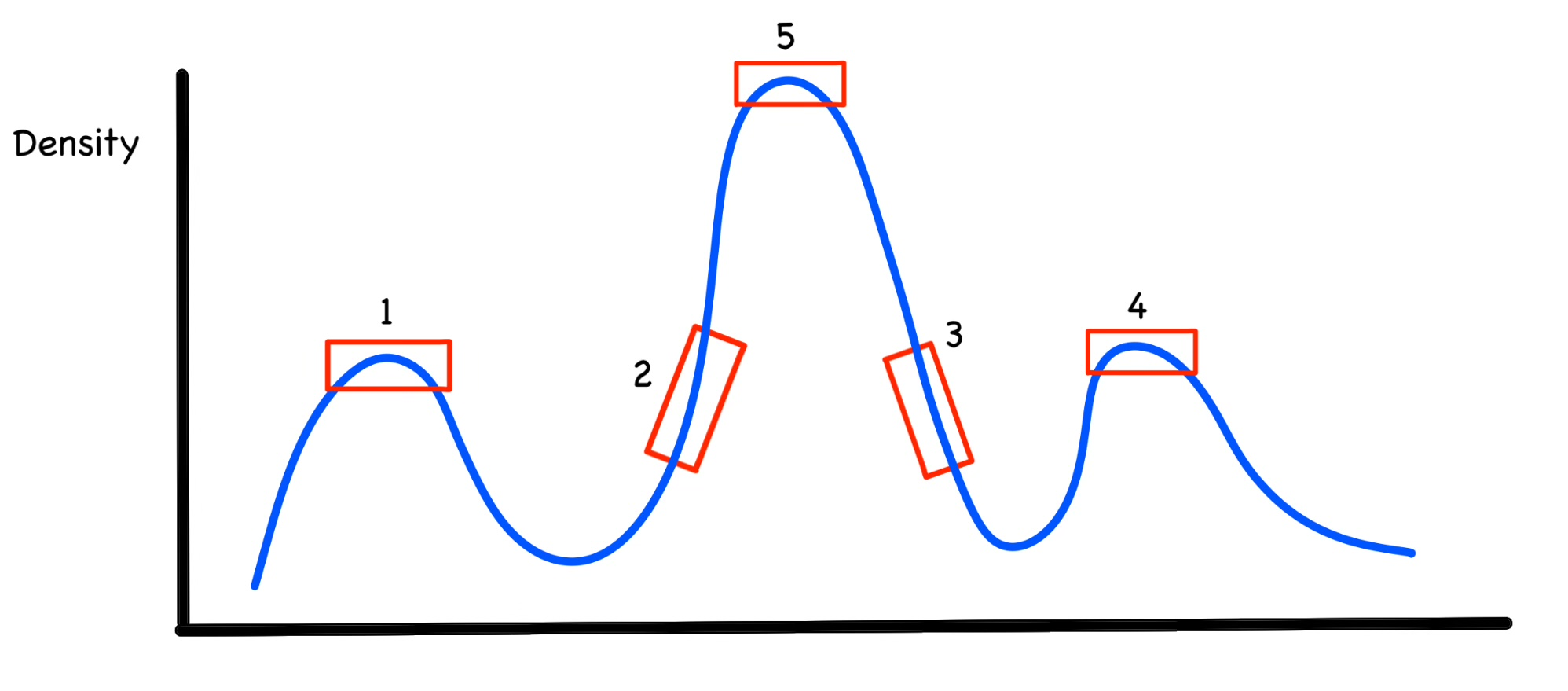
위 사진은 $\eta_1=\eta_2=\eta_3=\eta_4$(1~4번까지 같은 density를 가지고, 5는 다른 Density를 가진다)라고 가정하겠습니다.
그렇게 되면 $\lambda$를 계산하기 위해 최소 거리 $\mu$를 계산해야 합니다.(2번,3번 다음의 포인트가 바로 저 네모난 박스라고 하고 거리를 계산하겠습니다. 저 네모난 두 박스는 1,2,3,4보다는 Density가 더 높음)
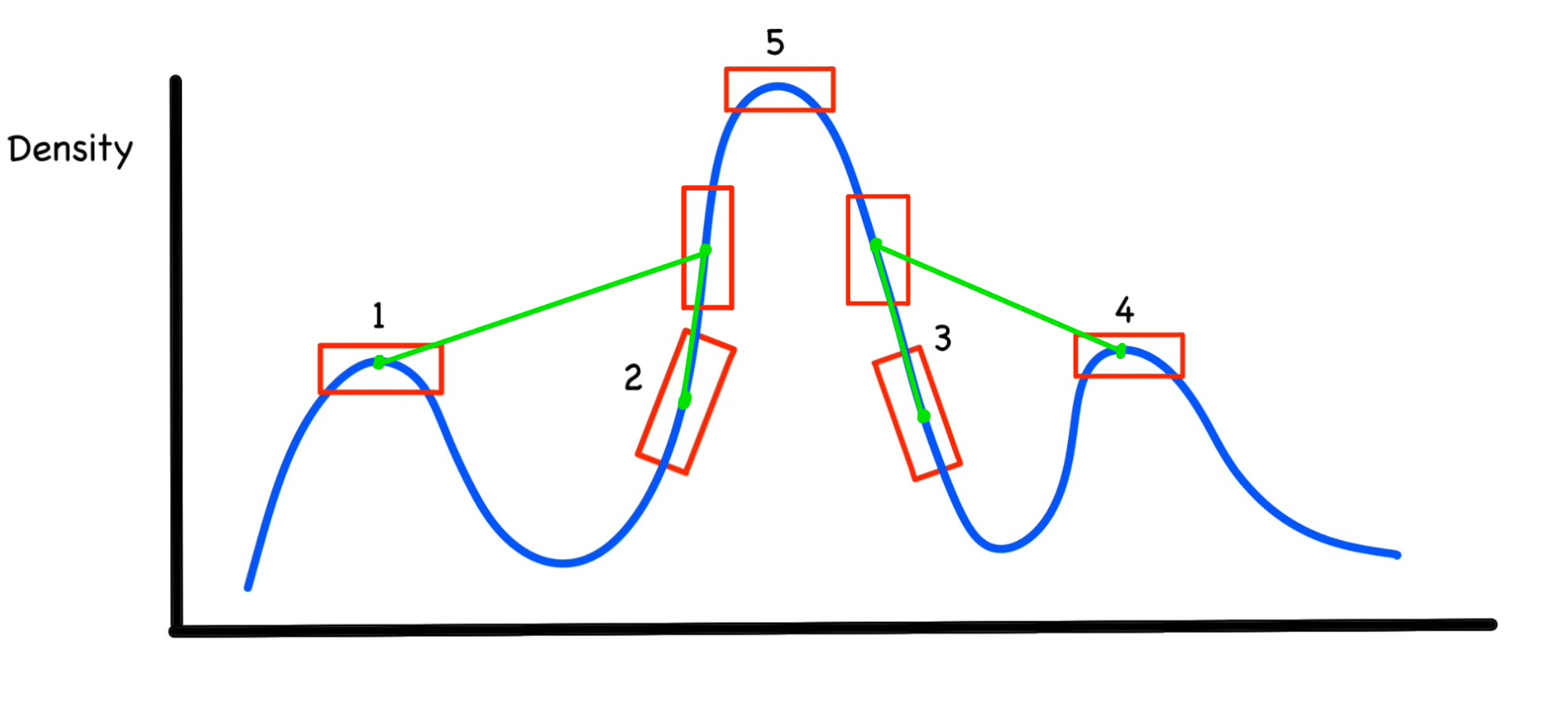
$\mu_1,\mu_2,\mu_3,\mu_4$를 위의 식에 대입해보면 초록색 선이 거리가 될 것입니다. 1,2,3,4에 대해서 계산해보면 대략 $\mu_1,\mu_4,\mu_2,\mu_3$ 이 순서로 클 것 같습니다.(최소 거리를 계산해야하기 때문에 1,4번은 거리가 멀고 2,3번은 가까운 것을 알 수 있습니다!)
클러스터의 중심을 계산하기 위해 $\lambda$를 계산하게 되면 $\lambda_5,\lambda_1,\lambda_4,\lambda_2,\lambda_3$이 순서로 될 것이고 아마도 더 많은 샘플에서 수행하게되면 클러스터의 중심인 1,3,5만 클러스터링이 될 것 입니다! 그리고 나서 나머지 샘플들은 1,3,5 클러스터에 더 가까운 곳으로 할당이 된다고 생각하시면 됩니다!
Proposed Peak-based Undersampling Algorithm
이제는 DPC 알고리즘을 살펴보았으니 이 알고리즘을 통해 어떻게 Undersampling을 수행했는지 살펴보도록 하겠습니다.
- 다수 클래스 데이터에 DPC 알고리즘을 적용시켜 e개의 클러스터 생성
- 각 클러스터의 중심에서 소수 클래스와의 거리와 밀도를 계산
- 새로운 측정값 $H_i$를 사용하여 다수클래스에서 가장 효과적인 샘플을 선택
- $H_i=u×dens_i+v×dist_i,\ \ \ \ \ where \ \ \ \ \ u+v=1$
- $dens_i = \sum_{j \in \text{cluster}_i} \eta_j$
- $dist_i = \sum_{q \in \text{minclass}} d(p, q)$ $p : centroid\ of\ cluster_i$
- $H_i=u×dens_i+v×dist_i,\ \ \ \ \ where \ \ \ \ \ u+v=1$
- $H_i$값이 높은 샘플 중 서로 너무 가깝지 않은 샘플을 선택합니다.
- 선택 기준은 $L = \{ x_i \mid x_i, x_j \in H \text{ and } d(x_i, x_j) > \theta \}$
- 선택된 샘플과 Minority class data를 병합해 수정된 데이터셋을 생성합니다. 이 데이터는 여전히 불균형 하지만, 원본 데이터보다는 불균형 비율이 낮습니다.(아마 분류기를 계속 학습하면서 불균형이 완화될 것이라 보입니다.)
Proposed OUBoost Algorithm
이제 저자가 제안한 OUBoost 알고리즘의 전체 흐름을 살펴보겠습니다. 위에는 Undersampling을 위한 방법론을 소개했지만, OUBoost는 소수 클래스를 SMOTE를 사용해 데이터 생성하기 때문에 두 기법을 결합하여 알고리즘이 어떻게 진행되는지 살펴보겠습니다!
- 데이터셋 분리 및 오버샘플링
- 원본 데이터셋 S를 소수 클래스와 다수 클래스로 나눕니다.
- SMOTE를 사용하여 소수 클래스에서 합성 데이터를 생성하고 이를 원본 데이터셋에 추가합니다.
- 다수 클래스 언더샘플링
- 제안된 Peak 기반 언더샘플링 알고리즘을 사용하여 다수 클래스에서 샘플을 선택합니다.
- 임시 데이터셋 생성
- 소수 클래스의 모든 샘플과 다수 클래스에서 선택된 샘플을 결합하여 새로운 임시 데이터셋 $S'_t$을 만듭니다.
- 이 데이터셋은 각 부스팅 단계에서 약한 학습기(weak learner)를 훈련하는 데 사용됩니다.
- 이때 불균형 비율이 되도록 임시 데이터셋 생성(불균형 비율은 우리가 선택할 수 있음)
- 만약 불균형 비율이 2:1이라고 하면, 생성된 소수 클래스의 데이터 수와 제거되고 남은 다수 클래스 데이터 수의 비율이 2:1이 되도록 데이터 정제
- 가중치 업데이트 및 반복
- 각 단계에서 약한 학습기의 예측 오류율 $\epsilon_t$을 계산합니다.
- 오류율을 기반으로 가중치 업데이트 매개변수 $\alpha_t$를 계산 $\alpha_t=\frac{\epsilon_t}{1-\epsilon_t}$
- 데이터셋 S의 각 샘플에 대해 가중치를 업데이트하고 정규화합니다.
- 최종 모델 생성
- T번의 반복 후, 최종 모델은 각 약한 학습기의 투표 결과를 기반으로 결정됩니다
- $H(x) = \arg\max_{y \in Y} \sum_{t=1}^{T} h_t(x, y) \log \frac{1}{\alpha_t}$
- T번의 반복 후, 최종 모델은 각 약한 학습기의 투표 결과를 기반으로 결정됩니다
Results
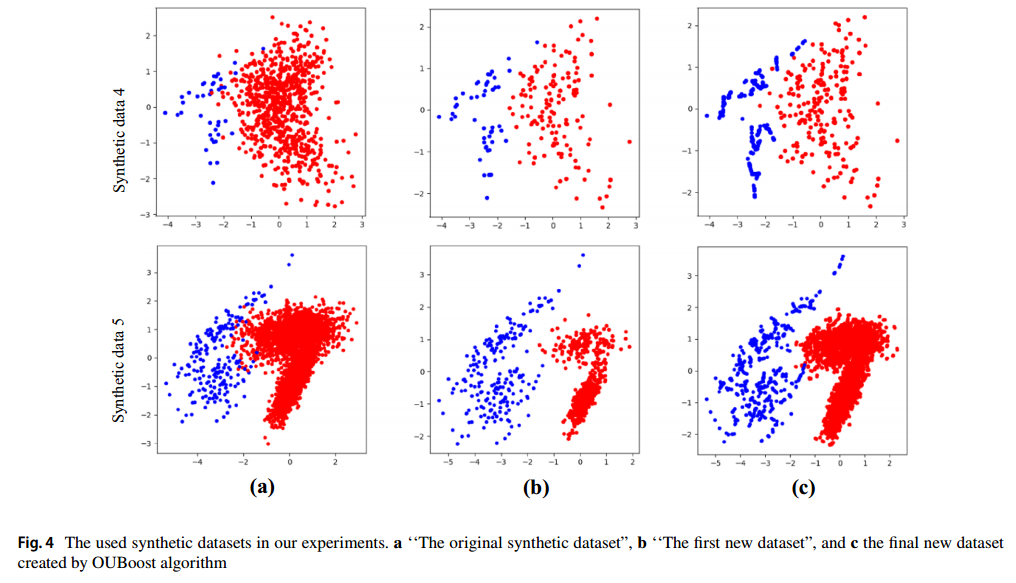
위 그림은 OUBoost 과정이 진행되면서 데이터 생성, 제거 과정을 표현한 그림입니다. (빨간색 : 다수 클래스, 파란색 : 소수 클래스)
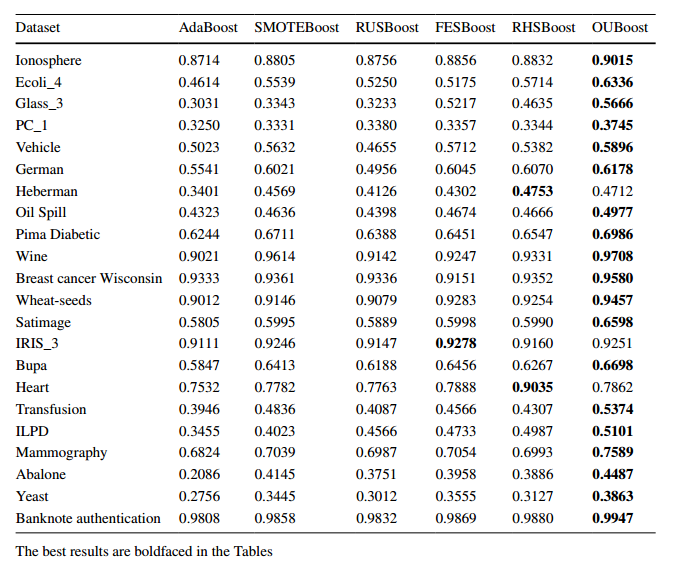
실제 불균형 데이터에 대해서 OUBoost를 적용한 모델과 다른 모델들에 대해서 F-score를 비교해보았습니다. 대부분의 경우 OUBoost의 성능이 우수한 것을 볼 수 있었습니다.
불균형 상황에서 잘 분류할 수 있다는 것은 큰 강점인 것 같습니다. 제조, 금융, 의료업에서는 아주 도움이 되는 모델이라고 느꼈습니다.
감사합니다.
참고문헌
'논문 리뷰 > Machine Learning' 카테고리의 다른 글
| SMOTEBoost : Improving Prediction of the Minority Class in Boosting (1) | 2024.11.18 |
|---|---|
| [논문 리뷰] Double random forest(DRF) (0) | 2024.10.16 |