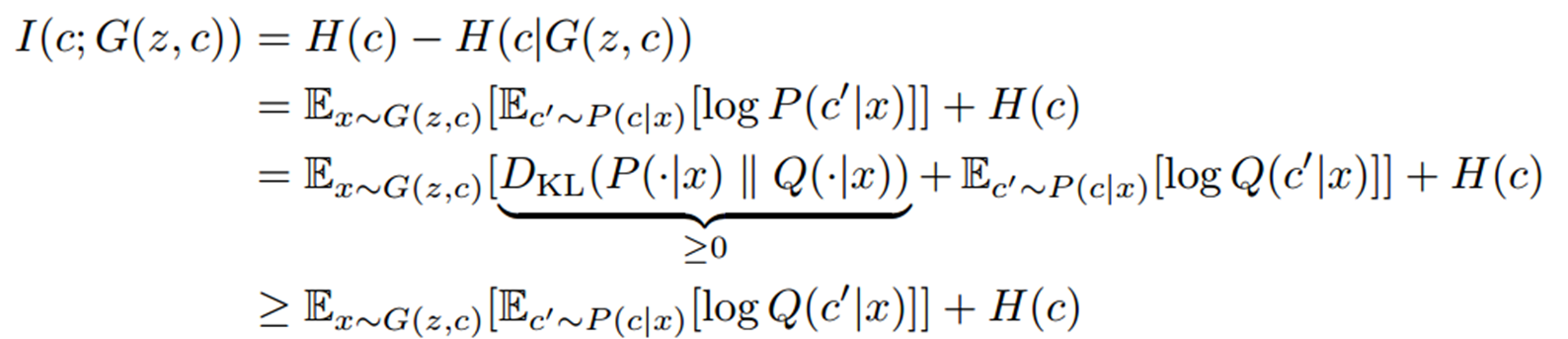InfoGAN은 기존의 GAN모델을 확장해서 분리가능한 변수를 학습할 수 있습니다. 예를 들어 사람의 이미지를 생성한다고 할 때 눈, 코, 입 모양 등이 사람 이미지 생성하는데 분리된 변수로 볼 수 있습니다.
위 사진처럼 기존의 GAN 모델은 Generator에 들어가기 전에, noise vector만 들어갔다면, InfoGAN에서는 noise vector와 latent code라고 불리는 c라는 vector가 추가로 들어갑니다. (사람 이미지라고 생각했을 때, c는 눈, 코, 입 모양이라고 할 수 있습니다.)
위 사진은 InfoGAN의 Objective function입니다. 기존의 GAN의 Objective function에서 Mutual Information이 추가가 됩니다. Mutual Information term을 전개해보면 아래와 같은 사진처럼 나오는데 이때 우리는 Posterior을 모르기 때문에 Posterior과 근사할 수 있는 우리가 흔히 알고 있는 분포(Gaussian distribution)을 사용하여 두 분포 간 거리가 좁혀지도록 Q의 parameter(mu, var)을 업데이트 하여 Loss를 최소화 하도록 합니다.
이 부분을 설명하는 이유는 CTGAN에서 InfoGAN을 결합할 term이라서 설명했습니다.
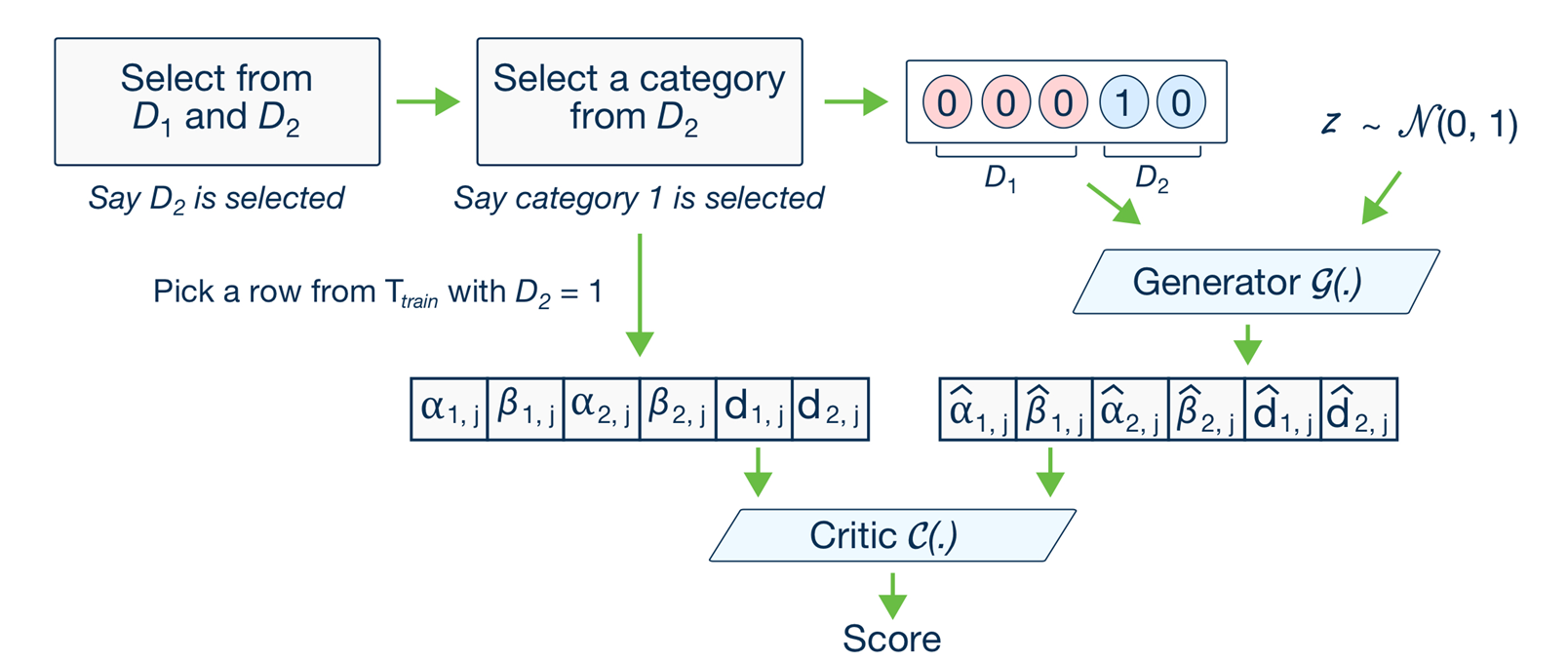
그럼 이제 저희가 제안한 모델을 살펴보겠습니다. 아래 사진은 CTGAN 모델의 아키텍처입니다.
CTGAN의 아키텍처
이 부분에서 어떻게 InfoGAN의 개념을 도입할것인가? → Generator의 input vector에서 conditional vector, noise vector 외에 InfoGAN의 latent code인 c를 도입하는 것 입니다.
여기서 c를 넣는 이유는 InfoGAN 모델을 생각해보면 c가 분리가능한 변수를 학습할 수 있었기 때문입니다.
즉, InfoGAN에서 latent code인 c를 넣어서 사람 얼굴을 생성한다고 할 때 이 c는 사람의 눈, 코, 입 등 중요한 변수를 독립적으로 학습합니다. 또한 c의 값을 변화시킬수록 눈, 코, 입 모양이 달라지는 다양한 이미지 데이터가 생성되게 됩니다.
그러면 tabular data를 생성할때도 c를 넣으면 Tabular data에서 중요하게 생각되는 변수가 c 값에 따라 변하지 않을까? 그러면 어떤 변수에 대해서 중점적으로 학습하는지 알게 될 것 같다고 생각했습니다.
input에다가 c를 추가했기 때문에 Objective function에는 기존의 CTGAN 모델의 Objective function에 Mutual information term이 추가가 됩니다.(Mutual Information term을 추가하여 G(z,c)가 c에 대한 정보를 많이 가지도록 합니다.) 이때 $\lambda$는 hyperparameter입니다.
아까 InfoGAN에서 Posterior을 직접구할 수 없었기 때문에 Q라는 보조분포를 사용했기때문에 저희가 제안한 모델에서도 Q라는 Network를 추가해줍니다. Q(우리가 흔히 아는 분포, Gaussain distribution)를 실제 Posterior과 가깝게 만들도록 mu와 var을 업데이트 합니다.
이렇게 최종적으로 모델을 만들었습니다. 그러면 이렇게 만든 모델이 실제로 데이터에서 어떤 변수를 중점적으로 학습하는지, 그리고 기존의 CTGAN 모델과 비교해서 성능이 어떻게 되는지 확인해보도록 하겠습니다.
Experiments
실험을 위해 Adult data 사용하며 Decision Tree Classifier 사용하여 F1-score 계산하였습니다. Adult data : 6개의 이산형 변수, 9개의 범주형 변수로 구성되었습니다.
Method
F1-score
CTGAN
0.5271
Proposed Method
0.5606
[코드 부분은 아래 게시글에서 확인하실 수 있으십니다. 링크 첨부합니다.]
위 표는 실제로 코드를 짜서 F1 score를 확인했습니다. 이때 c는 1로 두고 모델을 학습했는데, c는 원하는 개수로 설정할 수 있습니다.(c가 변수의 수보다 많지만 않으면 됨)
성능은 확실히 좋아진 것을 알 수 있었지만, InfoGAN에서는 이미지 데이터 생성이므로 c가 어떤 특징을 학습했는지 시각적으로 보여졌지만, Tabular data는 수치적으로 보이다 보니 c가 어떤 변수를 중점적으로 학습했는지는 확실하게 알 수 없었습니다. 이 부분이 조금 아쉬웠습니다.
Limitation
저희가 제안한 모델에는 성능적으로는 향상했다고 할 수 있지만, 왜 그렇게 향상이 됐는지 논리적으로 설명을 할 수 없었습니다. latent code인 c를 추가했지만, 이 c가 Adult data에서 어떤 변수를 중요하게 학습했는지 확인할 수 없었고, 과연 다양한 데이터를 생성했다? 라는 말도 납득시키지 못했습니다. 이미지 데이터는 얼굴 모양이 다른 데이터가 생성되었기 때문에 다양한 데이터를 생성했다고 할 수 있지만, Tabular data는 수치 데이터 이기 때문에 과연 변수의 값이 변했다고 다양한 데이터가 생성이 된게 맞는지? 의심해볼 필요가 있습니다.
논리적으로 보완할 수 있다면 모델의 성능은 향상되었기 때문에 어느정도 의미가 있다고 볼 수 있을 것 같습니다.
Continuous columns은 multiple modes(여러개의 봉우리)를 가지고 있으며 Discrete columns은 각 카테고리 수가 불균형(암 환자 : 5%, 정상 환자 : 95%)하게 되어있으면 Deep neural network 모델은 모델링 하는데 어려움을 겪습니다.
저자는 CTGAN이라는 모델을 제안했으며 이 모델은 위에서 제시한 문제점을 해결하기 위해 Conditional Generator를 사용한다고 합니다. 모델이 어떤 구조인지 살펴보도록 하겠습니다.
Challenges with GANs in Tabular Data Generation Task
Table $T$(Tabular data)에 대한 column 정의는 다음과 같습니다.
Continuous columns : $\{C_1,...,C_{N_C}\}$
Discrete columns : $\{D_1,...,D_{N_d}\}$
Total columns : 총 $N_C$+$N_d$ 즉, N개의 컬럼을 갖고 있다고 보면 됩니다.
각각의 컬럼은 Random variable(확률변수)로 생각하고 각 컬럼은 unknown joint distribution $\mathbb{P}(C_{1:N_c},D_{1:N_d})$라고 합니다. 즉 각 컬럼 간 독립이 아니라 컬럼끼리 관계를 갖고 있다고 해석 할 수 있을 것 같네요
One row $\bold{r}j=\{c{1,j},...,c_{N_c,j},d_{1,j},...,d_{N_d,j}\},j\in\{1,...,n\}$
Table $T$를 $T_{train}$과 $T_{test}$로 나누고, $T_{train}$으로 G를 학습한 후에 G를 사용해 각 행을 독립적으로 생성한 집합을 $T_{syn}$이라 합니다.
저자는 2가지 측면으로 Generator의 효율성을 판단한다고 합니다!
Likelihood fitness : $T_{syn}$로 생성한 컬럼이 $T_{train}$와 같은 joint distribution 따르는지
Machine learning efficacy : $T_{train}$로 모델을 학습하여 $T_{test}$ 평가한 성능과 $T_{syn}$로 모델을 학습하여 $T_{test}$ 평가한 성능이 비슷한지?
기존의 GAN 모델을 사용해 Tabular data를 생성하면 문제가 있다고 했는데, 어떤 문제가 있는지 확인해 보겠습니다. 총 5가지 도전과제가 있습니다.
Mixed data types : 연속형, 이산형 columns을 동시에 생성하기 위해서는 Softmax, Tanh 함수를 적용해야 합니다. Softmax는 이산형 columns, Tanh는 연속형 columns를 처리하기 위한 함수입니다.
GAN의 경우 Mixed data를 처리할 때 최적화 문제가 발생한다고 합니다! GAN을 학습시킬 때, 이산형 데이터와 연속형 데이터를 동시에 다루기 위해 손실 함수를 적절히 조합하고 최적화해야 합니다. 이산형 데이터를 위한 손실은 일반적으로 분류 문제에 사용되는크로스 엔트로피같은 함수가 적합하고, 연속형 데이터에는평균 제곱 오차와 같은 함수가 적합합니다. 이 두 손실 함수를 적절히 조합하는 것은 도전적이라고 합니다.
Non-Gaussian distributions: 이미지 데이터의 경우 pixel들은 Gaussian과 유사한 분포를 따르기 때문에 [-1,1]의 범위로 normalizing할 수 있지만, Continuous 컬럼의 값들은 Gaussian 분포를 따르지 않아서 Tanh로 normalizing 시키면 vanishing gradient problem문제가 발생합니다.
왜 gradient problem문제가 발생하느냐? → 만약 3개의 mode를 가진다고 가정해봅시다. 각각의 mode는 $N(0,1)$, $N(5,1)$, $N(10,1)$의 분포를 갖는 데이터들이 존재한다고 하면 이 값들을 Tanh로 normalizing 시켜버리면 $N(0,1)$과 $N(10,1)$ 분포에 존재하는 데이터 들은 각각 -1과 1에 근사하는 값을 가집니다.
근데 Tanh함수는 아래와 같은 그림을 나타냅니다. 여기서 -1과 1에 근사하는 값의 기울기는 거의 0이 되겠죠. 그래서 Backpropagation과정에서 기울기가 소실된다고 말하는 것 같습니다. (기울기 소실이 발생하면, 네트워크의 특정 부분에서 가중치가 업데이트 되지 않거나 매우 느리게 학습되어, 전체적인 학습 과정의 효율성과 효과가 크게 저하됩니다.)Tanh 함수
Multimodal distributions : 여러개의 mode(봉우리)를 가지고 있어서 Kernel Density Estimation(KDE)로 mode를 추정합니다. 기존의 GAN은 이런 Multimodal distribution을 모델링하는데 어려움을 겪는다고 합니다.
그러면 GAN 모델은 Multimodal distribution을 모델링하는데 왜 어려움을 겪을까요? 모드 간 균형: GAN은 경향적으로 분포의 주된 모드에 초점을 맞추고, 덜 대표적인 모드는 무시할 수 있습니다. 이로 인해 데이터의 다양성과 복잡성을 완전히 포착하지 못할 수 있습니다.
Learning from sparse one-hot-encoded vectors : 새로운 샘플들을 생성하면 모델은 softmax를 사용하여 각 카테고리의 확률(e.g. [0.7,0.2,0.1])을 출력합니다. 하지만, 실제 데이터는 one-hot vector(e.g. [1,0,0])로 표현됩니다.
이게 무슨 문제가 되냐? 실제 데이터는 원-핫 벡터로 매우 희소한(0이 많음) 반면, 생성된 데이터는 확률 분포로 인해 상대적으로 덜 희소합니다. 이러한 차이는 판별자(discriminator)가 실제 데이터와 생성된 데이터를 구별하는 데 사용될 수 있습니다.
위의 예시의 경우 one-hot vector에서 1의 카테고리가 생성된 모델에서는 0.7의 확률을 가지니 ‘진짜’라고 판단을 해야하는데, 이런 특성을 보지 않고 그저 벡터의 희소성만 확인하여 생성된 데이터를 가짜라고 구별하게 됩니다. 이렇게 되면 [0.99,0.005,0.005]의 데이터여도 희소하지 않기 때문에 가짜라고 구별하게 돼서 GAN 학습 과정에서 문제가 발생할 수 있는 것 같습니다. D입장에서는 [0.99,0.005,0.005]도 가짜라 생각해 0을 출력하니 Maximize가 되지만, G입장에서 보면 E_{z\sim p(z)}[log(1-D(G(z)))]값이 E_{z\sim p(z)}[log(1-0)]=0이 되어 Minimize가 되지 않습니다. 즉, 제대로 학습이 안되는거죠.
Highly imbalanced categorical columns : 이산형 컬럼에서 category의 빈도가 불균형 하여 mode collapse(모드 붕괴)가 일어납니다. 즉, 생성자가 데이터의 다양성을 반영하지 못하고 주로 주요 카테고리만을 반복적으로 생성하는 현상입니다. 이는 GAN이 다양한 데이터 패턴을 학습하고 재현하는 데 실패하게 만듭니다.
그리고 minor category를 생성과정에서 누락해도 데이터의 분포의 변화는 거의 없어서 판별자가 이것을 감지하기는 어렵다고 합니다! 그렇게 되면 minor category 데이터는 거의 생성이 되지 않는 문제가 발생하여 전체 데이터의 다양성을 학습하지 못하고 major category의 데이터만 생성하게 되는 문제가 발생하는 것 같습니다.
Conditional Generator and Training-by-Sampling : Imbalanced(4,5) 문제 해결 (Discrete columns)
Mode-specific Normalization
Non-Gaussian, Multimodal 문제였던 것을 확인해 봅시다. $T$에서 Continuous 컬럼은 아래 그림처럼 여러개의 mode를 갖는다고 했습니다.
위 그림은 3개의 mode가 존재하니 3개의 sub distribution으로 나누고, 각각의 distribution에서의 평균 : $\eta_k$, Weight : $\mu_k$, standard deviation : $\phi_k$로 설정합니다.
$c_{i,j}$ : i 번째 컬럼에 해당하는 j번째 행 데이터로 각각 Gaussian mode에서 발생할 확률은 $\rho_k$입니다.
그림에선 $\rho_3$ 확률이 가장 높으므로($c_{i,j}$는 $\rho_3$의 분포에서 나왔을 것!) $\beta_{i,j}=[0,0,1]$로 표현하고 $\alpha_{i,j}$도 식에 대입합니다.
기존의 One row $\bold{r}_j$를 다시 재표현 하면 아래와 같습니다.
여기서 $d_{1,j}$ 이전의 부분들은 continuous columns이고, mode-specific Normalization을 통해 구할 수 있습니다.
$d_{1,j}$ 이후의 부분들은 discrete columns로 구성되었으며 one-hot encoding 되어있습니다.
Conditional Generator and Training-by-Sampling
기존의 GAN에서는 minor category를 고려하지 못하는 문제가 있었기 때문에 Conditional Generator를 도입합니다. Conditional Generator를 통해 특정 이산형 컬럼의 값에 따라 데이터 행을 생성할 수 있도록 하는 것입니다. CGAN과 유사한 방식이라고 생각하시면 됩니다! 그러면 이제 어떻게 Condition을 줄 것이냐? 바로 Training-by-Sampling 방법으로 Condition을 줄 것입니다! ( 이 방식으로 불균형 한 문제를 해결할 수 있습니다.)
아래는 Training-by-Sampling 방식입니다!
각각 단계를 자세히 보겠습니다.
$N_d$ 개의 discrete columns 중에 랜덤으로 한개의 컬럼을 선택 $i^*$
선택된 Discrete columns에 대해 PMF(확률질량함수) 구함
PMF를 따르는 확률 분포에 따라 하나의 카테고리를 선택한다. 이를 $k^$라고 합니다. 아래는 $k^$ 선택하는 과정입니다.(카테고리가 2개가 있다고 가정)
첫 번째 카테고리 빈도 : 100
두 번째 카테고리 빈도 : 10
첫번째 카테고리 확률 : 100/110 ~ 0.9
두번째 카테고리 확률 : 10/110 ~ 0.1
그대로 사용하는게 아니라 log 변환 수행
log(100) ~ 4.61, log(10) ~ 2.3
첫번째 카테고리 확률 : 4.61/6.91 ~ 0.667
두번째 카테고리 확률 : 2.3/6.91 ~ 0.333
log의 유무에 따라 뽑힐 확률이 달라지는게 보이시죠! log변환을 통해 minor category가 뽑힐 수 있는 확률을 늘려주었습니다!
Conditional vector 생성 만약 2개의 이산형 컬럼이 존재하고, 첫번째 컬럼에는 3개의 카테고리, 두번째 컬럼에는 2개의 카테고리가 있는데, 2번째 컬럼의 첫번째 카테고리가 선택되었다면 Conditional vector는 다음과 같습니다. Conditional vector : [0,0,0,1,0]
그리고 여기서 저희가 Generator loss를 추가해 주는데, conditional vector로 2번째 컬럼의 1번째 카테고리가 주어졌을 때 이 조건에 맞는 이산형 벡터를 생성해야하는데, 잘못된 벡터가 생성되었을 수도 있으니 그 손실을 감소시키기 위해 cross-entropy 손실을 추가합니다!
위 방법으로 기존의 문제였던 5(Highly imbalanced categorical columns)번 문제를 해결할 수 있었습니다.
그러면 이제 4번문제가 남아있는데, 기존의 GAN에서 Softmax 함수를 사용했다면, Gumbel-Softmax 함수를 사용해서 sparse한걸로 판별했던 문제를 해결할 수 있었습니다.
Gumbel-Softmax 내용은 Chat GPT를 사용하였습니다
Gumbel-Softmax는 각 범주에 대한 확률을 계산한 후, Gumbel 분포를 통해 샘플링하여 one-hot vector와 유사한 출력을 생성할 수 있게 합니다. 이를 통해 신경망은 연속적인 방식으로 역전파를 수행하면서도, 이산적인 범주형 데이터를 효과적으로 생성할 수 있습니다.
기존의 GAN의 도전과제들을 다 해결하였습니다. 이제 두 가지 평가지표로 성능이 확실한지 파악해보겠습니다.
Evaluation Metrics and Framework
두가지 평가지표
Likelihood fitness metric
Machine learning efficacy
Likelihood fitness metric
과정은 아래 사진과 같습니다.
Synthetic Data Generator: 이 생성기는 학습 데이터를 기반으로 합성 데이터를 생성합니다.
합성 데이터(Synthetic Data): Generator에 의해 생성된 데이터입니다. 이 데이터는 실제 데이터와 유사한 데이터 입니다
Likelihood $L_{syn}$: 합성 데이터의 likelihood를 계산하여, 이 데이터가 실제 분포를 얼마나 잘 따르는지 평가합니다.
Likelihood $L_{test}$: 테스트 데이터에 대한 likelihood를 계산하여, 합성데이터가 실제 데이터를 얼마나 잘 모델링하는지 평가합니다.
Machine learning efficacy
실제 데이터에서 효율 확인
이번에는 합성데이터를 이용해 Decision Tree, Linear SVM, MLP를 사용하여 학습한 후 Test data에 대해 예측을 수행하여 Accuracy와 F1, $R^2$ 확인!
Result
TVAE와 CTGAN에서 우수한 성능을 보이고 있음!
그리고 CTGAN에서는 Generator에서 input data가 아닌 noise를 사용하기 때문에 Privacy 문제에 유용하다고 합니다(TVAE보다)
GM Sim, BN Sim에서 Likelihood 값이 커야 두 분포가 유사하다고 볼 수 있습니다. CTGAN이나 TVAE가 역시 다른 모델에 비해 likelihood값이 대략적으로 큰 것을 볼 수 있습니다!
InfoGAN이란 기존의 GAN 모델에서 정보이론(information-theoretic)의 개념을 추가하여 Disentangled representation을 학습할 수 있도록 하는 모델입니다.
Disentangled representation이란?
데이터의 특징(feature)이나 변수가 서로 분리되어 표현된다는 것을 의미합니다.
사람의 얼굴 이미지를 다룬다고 할때 사람의 표정, 눈 색상, 헤어스타일, 선글라스 유무, 숫자 이미지를 다룬다고 할때 숫자의 크기, 두께(thickness), 각도(angle) 등의 특징이 분리되어 표현된다면 disentangled representation이라고 합니다.
분리된 feature를 통해 사람의 얼굴 이미지를 생성
기존의 GAN 모델에서는 Input data와 유사한 데이터를 만드는 것에 목적을 두었다면, InfoGAN은 유사한 데이터를 만들면서 데이터의 특징을 잘 학습하는데 중점을 둡니다.
잘 학습되게 된다면, 숫자 데이터에서 두께, 각도 등을 다르게 생성할 수 있게 된다는 큰 장점이 있습니다.
위 그림을 보면 (a),(c),(d)의 경우 InfoGAN의 결과이고, (b)는 Original GAN의 결과입니다. 변수에 약간의 값을 변경해서 넣어주게 되면 회전하는 것과 넓이가 커지는 것을 볼 수 있습니다. (위 그림에선 c2는 회전의 특징을 학습한 변수이며 c3는 넓이의 특징을 학습한 변수라고 생각할 수 있습니다.)
2. Abstract
‘learn disentangled representations’ 위에서 말했듯이 정보이론의 개념을 도입해 데이터의 특징을 잘 학습할 수 있도록 학습하는 것입니다.
maximizes the mutual information mutual information term을 maximize하는 것을 목표로 합니다. (Mutual information은 상호정보라 불리고 아래에서 자세하게 설명하겠습니다.)
lower bound of the mutual information 직접적인 mutual information term을 구할 수 없으므로 lower bound를 구해서 그 lower bound를 maximize하는 것을 목표로 합니다.
learns interpretable representations 실험결과에서 InfoGAN은 해석가능한 representation을 학습했다고 말하고 있습니다.
3. Background: Generative Adversarial Networks
GAN(Generative Adversarial Networks) 모델의 목적은 생성된 데이터 분포 $P_{G}(x)$ 가 실제 데이터 분포인 $P_{data}(x)$와 유사하게 학습하도록 하는 모델입니다.
그러기 위해서는 생성자(Generator)와 판별기(Discriminator)를 학습하게 되는데 생성자의 경우 noise를 입력으로 받아 생성자(G)를 통해 이미지를 생성하고, 판별기(D)는 입력으로 받은 데이터가 실제 데이터인지, G가 생성해낸 이미지인지 판별하게 됩니다.
생성자(G)의 입장에서는 실제 데이터와 아주 유사하게 만들어야 하고, 판별기(D)는 실제 데이터인지, 생성자(G)가 만든 데이터인지 구분을 잘 할 수 있도록 설계되어 있다고 생각하시면 됩니다! 이 내용을 식으로 쓰게되면 아래와 같이 표현할 수 있습니다.
GAN의 목적함수
이제 G와 D입장에서 minimization, maximizatinon하는 과정을 보겠습니다.
Discriminator : D의 입장에서는 실제 데이터를 1로 출력하고 생성된 데이터는 0이라고 출력하길 원합니다!
위 그림처럼 되면 maximization이 되겠지요!
Generator : G의 입장에서는 판별기(D)가 1로 출력해주길 원합니다!
첫 번째 항에는 G가 없으니 두 번째 항만 신경쓰면 됩니다! minimization해야하니 log0 에 수렴해야 가장 작은 값을 얻을 수 있겠죠!
4. Mutual Information for Inducing Latent Codes
GAN에서 noise vector(z)를 입력으로 받고 G가 데이터를 생성했었습니다. 하지만 이때 z에게 아무런 제약을 주지 않았습니다. 그렇기 때문에 Generator는 매우 꼬여있다(entangled way)고 볼 수 있습니다. 여기서 꼬여있다는 것은 z의 차원들이 data에서 의미를 가지는 feature와 대응되지 않는다고 볼 수 있습니다!
아래 사진처럼 얼굴 이미지를 생성할 때처럼 z의 차원들이 의미(특징)를 가지고 있지 않다는 것으로 보면 될 것 같습니다!
분리된 feature를 통해 사람의 얼굴 이미지를 생성
MNIST data의 경우만 봐도 0~9 숫자를 나타내는 digit type, 회전을 나타내는 Rotation, 너비를 나타내는 Width, 두께를 나타내는 thickness 등의 특징을 가지고 있음을 알 수 있습니다.
이런 특징에 대한 정보를 가지고서 이미지를 생성하면 원하는 데이터를 생성할 수 있지 않을까? 라는 생각에서 GAN의 확장모델인 InfoGAN이 만들어진 것입니다!
InfoGAN에서는 noise vector(z)를 두개의 파트로 나누어서 사용합니다.
압축할 수 없는 noise z 이 z는 생성된 데이터에 무작위성이나 변동성을 주입하기 위해 사용된다고 합니다. 데이터의 구조를 설명하진 않지만, 생성된 샘플의 다양성을 증가시키는 역할을 합니다.
데이터분포에서 특징을 가지는 latent code “c” 얼굴이미지를 생성한다고 할 때 표정, 눈 색상 등 의미를 가지는 feature를 c라고 생각하시면 됩니다. 또한 latent code c는 factored distribution을 가정합니다. factored distribution은 변수들과 독립성을 가정하고 확률분포로 표현합니다. $P(c_1,c_2,...,c_L)=\Pi_{i=1}^LP(c_i)$
저희는 이제 noise vector를 두 파트로 나누었으니 Generator에서는 z와 c를 입력으로 받아 생성해야겠죠! G(z) → G(z,c)가 됩니다!
🤔 However, in standard GAN, the generator is free to ignore the additional latent code c by finding a solution satisfying $P_G(x|c)=P_G(x)$
기존의 GAN의 모델에서는 아무런 제약을 주지 않아 $P_G(x|c)=P_G(x)$를 만족하는 solution을 찾기 때문에 c가 무시되게 됩니다.
이렇게 되는 것을 피하기 위해 우리는 추가로 제약을 걸어줘야 합니다! 그래서 저자는 information -theoretic regularization을 제안하였고, latent code c와 G(z,c)간의 상호정보량이(mutual information) 높아야 한다고 말하고 있습니다. 따라서 $I(c;G(z,c))$이 값이 높기를 원한다는 겁니다.(제가 초반에 정보이론개념을 추가할거라고 말한 부분입니다!)
정보이론에서 X와 Y 사이의 상호정보량(mutual information)은 $I(X;Y)$로 표현되고 Y 변수를 통해 X에 대해 얻어진 “정보량”이라고 하고 식은 아래와 같이 쓰일 수 있습니다.
동물의 특징이 주어졌을 때 동물을 예측하는것과 특징이 주어지지 않았을 때 동물을 예측하는 것 중 어느것이 더 ‘잘’ 예측할 수 있을까요? → 당연히 정보가 주어졌을 때 예측하기 쉽겠죠!(불확실성이 더 감소!) 이렇게 정보가 주어졌을 때 얼마나 더 잘 예측할 수 있는가를 불확실성의 감소량이라고 볼 수 있습니다!
만약 X와 Y가 독립이면
$I(X;Y)=\Sigma_{x\in X,y\in Y}P_{X,Y}(x,y)log(\frac{P_{X,Y}(x,y)}{P_{X}(x)P_{Y}(y)})$ 이 부분에서 $P_{X,Y}(x,y)=P_X(x)P_Y(y)$로 쓸 수 있기 때문에 $I(X;Y)=\Sigma_{x\in X,y\in Y}P_{X,Y}(x,y)log(1)$ =0이 되는 것을 알 수 있습니다!
직관적으로 해석해보면 동전을 던져서 나오는 결과를 생각해본다고 해보겠습니다.
첫 번째 동전을 던져서 앞면이 나왔다고 두 번째 동전이 앞면이 나올 확률이 바뀔까요? 아닙니다. 그대로 $\frac{1}{2}$인 것을 알 수 있죠. 즉, 두 번째 결과는 첫 번째 결과를 통해 얻어진 정보가 없다고 볼 수 있죠! 그렇기에 상호정보량은 0이라고 할 수 있습니다.
다시 돌아와서, 저희는 $P_G(x)$에서 뽑힌 x가 주어졌을 때, $P_G(c|x)$가 small entropy를 갖기를 원합니다!(small entropy는 정보의 불확실성이 적다는 것을 의미한다고 생각하시면 됩니다.)
그래서 기존 GAN의 목적함수에서 information-regularized term인 $I(c;G(z,c))$을 추가하여 이 값이 최대가 되도록 합니다! 식을 쓰면 아래와 같습니다.
GAN에서는 G를 minimization하도록 만들었으니 $I(c;G(z,c))$을 maximization하는 것 대신 -$I(c;G(z,c))$를 minimization하도록 term을 추가한 것입니다! ($\lambda$는 hyperparameter 입니다.)
5. Variational Mutual Information Maximization
이제 우리는 $I(c;G(z,c))$ term을 maximization[ -$I(c;G(z,c))$를 minimization하는 것과 같아서 maximization관점으로 보겠습니다.]해야합니다. 하지만, 우리는 이 식을 통해서 직접적으로 maximization할 수 없습니다. 왜그럴까요? 우선 $I(c;G(z,c))$ 식을 전개해 보겠습니다.
식이 되게 복잡해 보입니다… 차근차근 하나씩 살펴보죠!! 형광색으로 칠한 부분 먼저 보겠습니다.
$I(X;Y)$에서 {X ← c, Y ← G(z,c)}대입하시면 $I(c;G(z,c))$ 이렇게 위 식처럼 나오게 됩니다.
위와 같은 식($I(c;G(z,c))$)을 maximization하기 위해서는 $P(c|x)$의 분포에서 뽑은 샘플 $c'$이 필요합니다. 즉, 우리는 데이터가 주어졌을 때 그 데이터의 특징(헤어스타일, 표정 등)을 알고싶은 것입니다! 하지만 우리는 알지 못하기 때문에 auxiliary distribution(보조분포) Q를 사용하여 근사하려 합니다. 보조분포는 보통 우리가 흔히 알고있는 Gaussian distribution으로 설정합니다! 그렇게 $Q(c|x)$를 설정하게되면, $P(c|x)$의 분포와 $Q(c|x)$의 분포간 차이가 있겠죠?? 그래서 분포들 간 거리를 측정하는 지표로 KL divergence라는 함수로 거리를 측정합니다.
위의 식을 그대로 갖고와서 log에음수를 취해서 분모 분자를 바꿨습니다. 편의를 위해 $\frac{Q(c'|x)}{P(c'|x)}=Z$라고 설정하겠습니다.
$\mathbb{E}\left[-log(Z)\right]$로 표현이 됩니다. 그런데 이 식을 자세히 보면 $-log(x)$와 $\mathbb{E}$의 형태로 이루어진 것을 볼 수 있습니다. $-log(x)$는 convex function이기 때문에 Jensen’s inequality를 적용할 수 있죠!
마지막으로 $D_{KL}(P(|x)||Q(|x))$ 식은 항상 0보다 크기때문에 이 식을 삭제하면 저 부등호가 성립한다는 것도 알 수 있습니다! 결국 하고싶은건 $I(c;G(z,c))$을 maximization을 하고싶은데, $P(c|x)$를 알지 못하니까 보조분포인 $Q(c|x)$를 이용해서 lower bound를 만들고 저 lower bound를 maximization 하고자 하는 것 입니다! 이것을 variational mutual information maximization라 합니다.
하지만 여기서 또 한가지 문제점이 있죠. 저희는 $P(c|x)$를 모르기 때문에 $Q(c|x)$를 사용한다고 했는데, 마지막에 구한식을 보면 $c'$을 $P(c|x)$분포에서 뽑고있습니다.
저자는 이 Lemma를 사용하여 값 교묘하게 변경하였습니다!
🔑 Lemma 5.1 For random variables X,Y and function $f(x,y)$under suitable regularity conditions: $\mathbb{E}{x\sim X,y\sim Y|x}\left[f(x,y)\right]=\mathbb{E}{x\sim X,y\sim Y|x,x'\sim X|y}\left[f(x',y)\right]$.
약간의 트릭을 사용하여 이렇게 변환이 가능하다고 하네요! 이 자료는 고려대학교 임성빈 교수님께서 2가지 방식으로 증명해주신 자료입니다.
첫 번째 증명
2번째 줄에서 3번째줄에서 x→ x’ 으로 rename했는데, 확률변수를 바꾼게 아니라 적분할 때 변수 표기를 바꾼거에 불과하다고 합니다. 그래서 성립하는 것을 볼 수 있죠.
2번째 증명에서는 Law of total expectation(이중 기대값) 정리를 사용하여 증명하셨습니다.
Law of total expectation 증명을 먼저 보시고 아래의 사진을 참고하시면 됩니다!
$I(c;G(z,c))$을 maximization하는 것 대신에 lower bound인 $L_1(G,Q)$을 maximization하자!!
따라서 infoGAN의 최종 목적식은 다음과 같습니다. ($\lambda$는 hyperparameter입니다.)
6. Experiments
실험을 통해 저자는 2가지를 달성하고자 합니다.
첫 번째 : 실제로 mutual information이 maximization이 되는지
두 번째 : InfoGAN이 구분되고 해석 가능한 representation을 학습하는지(사람의 표정, 헤어스타일 등의 특징을 잘 학습했는지)
6-1. Mutual Information Maximization
latent codes c와 G(z,c)간의 mutual information을 평가하기 위해서 MNIST 데이터셋을 사용했습니다. $c \sim Cat(K=10,p=0.1)$의 분포로 설정하고나서 Lower bound를 각 iteration(반복)마다 $H(c)$값을 기록했습니다. $H(10) \approx 2.30$으로 빠르게 maximization되는 것을 확인할 수 있습니다.
Cat(카테고리 분포)의 pmf를 나타내면 다음과 같습니다.
Lower bound L1 over training iteration
6-2. Disentabgled Representation
MNIST 데이터셋에서 Disentabgled Representation을 잘 학습했는지 확인하기 위해 latent code $c_1,c_2,c_3$를 추가했는데 $c_1 \sim Cat(K=10,p=0.1)$이며 $c_2,c_3$변수는 연속형 변수로 $Unif(-1,1)$을 사용하였습니다.
$c_1$ 변수의 경우 label에 대한 정보도 없이 0~9까지의 숫자를 잘 생성해낼 수 있는 것을 볼 수 있었습니다.
$c_2,c_3$ 변수의 경우 $c_2$는 숫자의 rotation(회전)에 대한 변수이고 $c_3$는 숫자의 Width(너비)에 대한 변수인것을 확인할 수 있습니다. 논문에서는 $Unif(-2,2)$를 사용해서 결과를 보여주고 있습니다.(더 극명한 결과를 보여주기 위함입니다.) latent code가 이런 특징들을 잘 포착한 걸로 보아 Disentabgled Representation을 잘 학습했다고 볼 수 있습니다.
즉, InfoGAN을 통해서 Mutual Information Maximization, Disentabgled Representation을 모두 달성했다고 볼 수 있습니다!
7. Conclusion
이 논문은 “Information Maximizing Generative Adversarial Networks”(InfoGAN) 이라고 불리는representation 학습 알고리즘을 소개했습니다. supervision을 요구로 하는 이전의 접근방법들과 다르게, InfoGAN은 비지도학습으로 해석과 분리가능한 representation을 학습하였다는 것입니다. 또한 GAN과 연산시간이 거의 비슷하다고 합니다!