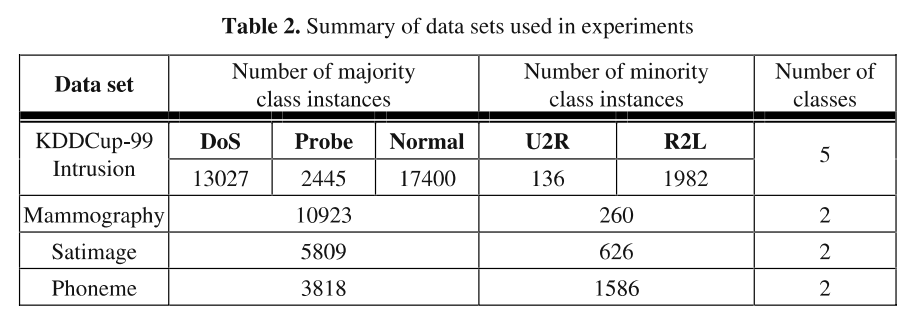
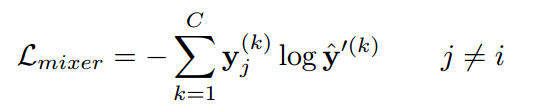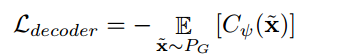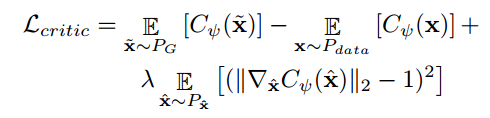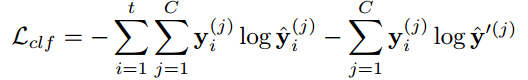이번 게시글에는 PKDD 2003 컨퍼런스에서 발표된 SMOTEBoost 논문에 대해 작성하겠습니다.
Abstract
불균형 상황에서, 데이터 수가 적은 소수 클래스를 학습하게 되면 모델은 다수 클래스에 편향되게 학습이 되어서 다수 클래스에 대한 예측 정확도는 높아지지만, 소수 클래스에 대한 예측 정확도는 매우 낮아지는 문제가 흔히 발생합니다. 이를 해결하기 위해 대표적으로 소수 클래스를 생성하는 SMOTE기법을 사용하는데, SMOTE 기법은 소수 클래스 데이터를 Oversampling하기 위해 설계된 기법으로 불균형 상황에서 소수 클래스 예측 정확도를 높이는 데 효과적인 기법입니다.
이 논문에서는 불균형 데이터 셋에서 학습을 위해 SMOTE 기법과 Boosting 기법을 결합하여 새로운 접근법을 제시하고자 합니다.
SMOTEBoost는 소수 클래스를 생성함으로써 부스팅 알고리즘의 가중치 업데이트 방식에 영향을 미치며, 이를 통해 skewed distribution을 보완할 수 있게 합니다.
기존의 부스팅 알고리즘은 오분류된 데이터에 가중치를 부여해 오분류된 데이터를 잘 학습할 수 있도록 작동합니다. 하지만, 데이터가 심각하게 불균형한 경우, 부스팅 알고리즘이 다수 클래스에 편향된 분포를 학습하게 되어 소수 클래스의 분류 성능이 낮아지는 문제가 발생합니다.
저자의 목표는 불균형 데이터에서 발생하는 편향(bias)을 줄이고, 소수 클래스의 데이터 경계를 더 잘 학습할 수 있는 모델을 만드는 것입니다.(편향을 줄이기 위해서는 데이터의 균형을 맞춰야 해서 가장 대표적인 기법인 SMOTE 기법을 사용해서 데이터를 생성한 것 같습니다.)
이제 SMOTE 기법과 Boosting 알고리즘을 어떻게 결합시켜 불균형 문제를 완화시킬 수 있었는지 살펴보도록 하겠습니다.
SMOTEBoosting 알고리즘
SMOTE기법 적용
각 반복에서, 소수 클래스 데이터에 대해 SMOTE 기법을 적용해 데이터를 생성합니다.
데이터 분포 업데이트 $D_t$
각 반복에서 생성된 샘플은 분포 $D_t$에 추가되어 사용됩니다. 소수 클래스 데이터가 추가되어서 소수 클래스의 가중치를 증가시키는 효과를 얻을 수 있습니다.
가중치를 증가시킨다는 것은 소수 클래스가 추가 되었으니 분류기가 다수 클래스로 편향되어 예측하지 않고 소수 클래스에 대해 조금 더 학습을 잘 할 수 있도록 돕는다는 것 같습니다.
SMOTE 데이터 삭제
각 반복단계에서 생성된 데이터는 제거되며 다음 부스팅단계에서 새롭게 생성된 데이터를 사용합니다.
생성된 데이터는 실제 데이터가 아니므로 노이즈가 될 수 있기 때문에 삭제하는 것 같습니다!
처음에는 생성된 데이터를 저장하여 계속 증가시키면 불균형이 완화되고 모델 성능이 좋아질거라고 생각했는데, SMOTEBoost의 목적을 확인해야 하는 것 같습니다.
SMOTEBoost의 목적은 데이터 생성하여 균형을 맞추는 것이 아닌 소수 클래스의 패턴을 학습할 수 있는 기회를 늘리는 것이기 때문에 굳이 맞출필요는 없는 것 같습니다. 그리고 사실 SMOTE로 생성한 데이토 실제 소수 클래스가 아닌데, 소수 클래스라고 지정하고 학습하게 되면 오히려 노이즈로 작용할수도 있는 것 같습니다!
Decision boundary
생성된 데이터는 Decision boundary 학습하는데 도움을 줍니다.
최종 분류기 학습
위 과정을 반복하여 최종 분류기를 학습하고, 데이터셋을 사용해 SMOTEBoost 적용하여 다른 기법들과 성능 비교
SMOTEBoost의 흐름을 설명해드렸고, 아래 사진은 알고리즘을 pseudo code로 작성한 것입니다.
Experimental Results
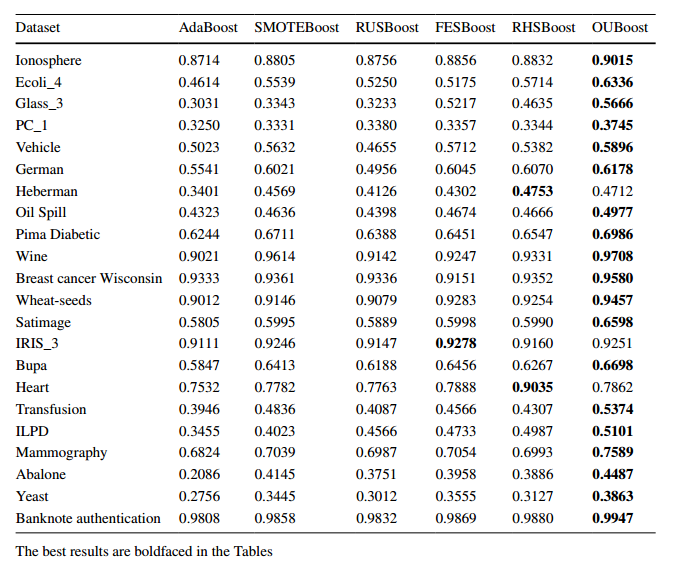
다음은 불균형한 데이터셋에서 SMOTEBoost의 성능을 다른 기법과 비교해보았습니다.
위 사진은 Mammography 데이터셋을 사용해서 F-value를 보았습니다. SMoteBoost에서 N=100으로 설정했을 때 분류기의 성능이 가장 좋은 것을 확인할 수 있습니다.
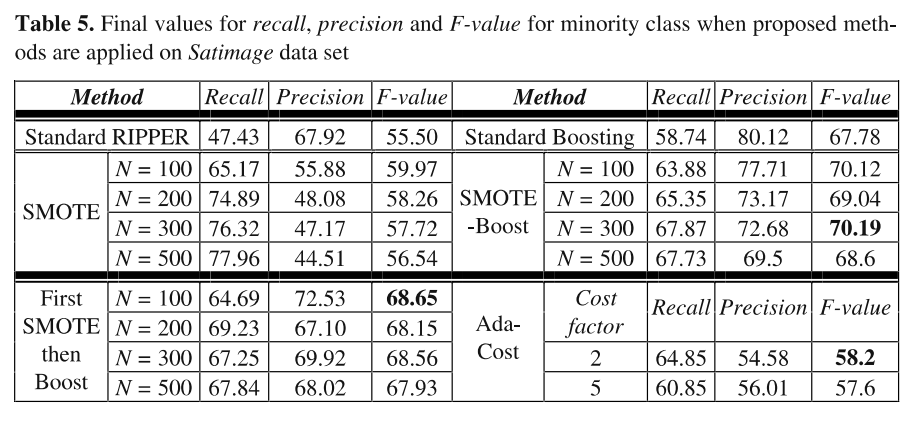
다음은 Satimage 데이터셋을 사용하여 F-value를 보았는데, 이때는 N=300으로 설정했을 때 성능이 가장 좋은 것을 확인할 수 있습니다.
이처럼 SMOTEBoost 모델이 기존의 SMOTE기법보다 성능이 좋은 것을 알 수 있으며 생성하는 숫자는 데이터셋마다 다른 것 같습니다.
확실히 SMOTE 기법만 사용하는 것보단 Boosting 모델을 결합하여 쓰면 성능이 좋은것을 알 수 있습니다.(아마도 부스팅의 목적이 오분류된 데이터를 더 잘 분류할 수 있도록 하는것이 목적이니까 소수 클래스를 잘 분류하는 모델을 만들어야하는 목적과 부합해서 좋은 시너지를 낼 수 있는 것 같습니다!)
이번 글에서는 2023년 5월 International Journal of Machine Learning and Cybernetics 저널에 게재된 OUBoost 논문에 대해 작성하겠습니다.
Abstract
현실 세계에서는 종종 불균형 데이터가 발생하며, 이는 다수 클래스를 잘 예측하지만 소수 클래스에 대해 분류기가 편향되어 예측 정확도가 떨어지는 문제를 야기합니다.
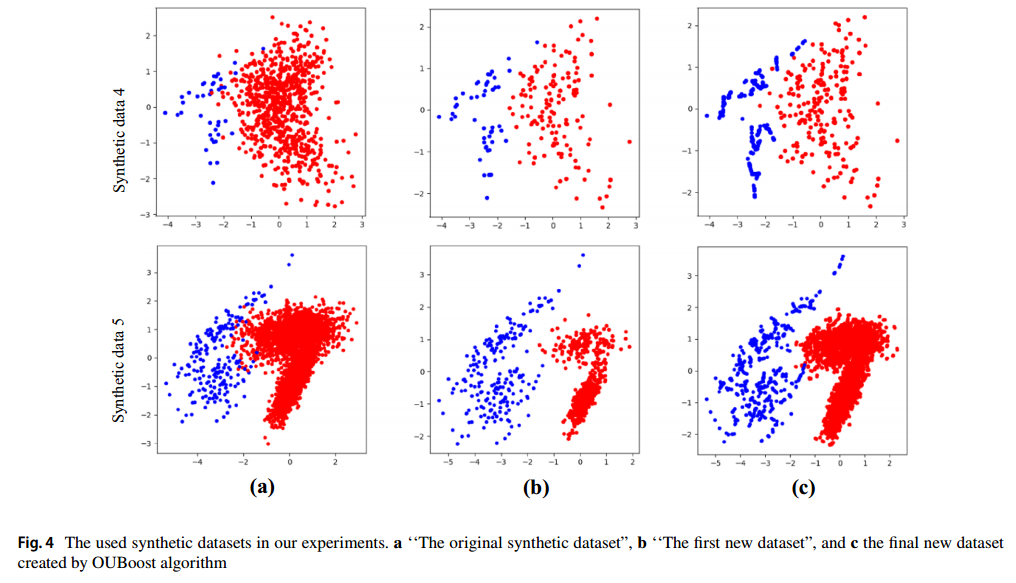
이 논문에서는 Peak clustering 방법을 사용해 다수 클래스의 데이터를 선택하여 undersampling을 수행하는 새로운 기술을 제안합니다. 또한, 소수 클래스에 대해 SMOTE 기반의 synthetic 데이터를 생성하고, 이를 부스팅 알고리즘과 결합한 새로운 OUBoost 알고리즘을 제시했습니다.
30개의 실제 불균형 데이터셋에 대해 여러 평가 지표를 사용하여 실험을 진행했으며, 대부분의 데이터셋에서 OUBoost를 사용했을 때 소수 클래스의 예측 성능이 개선되는 것을 확인했습니다.
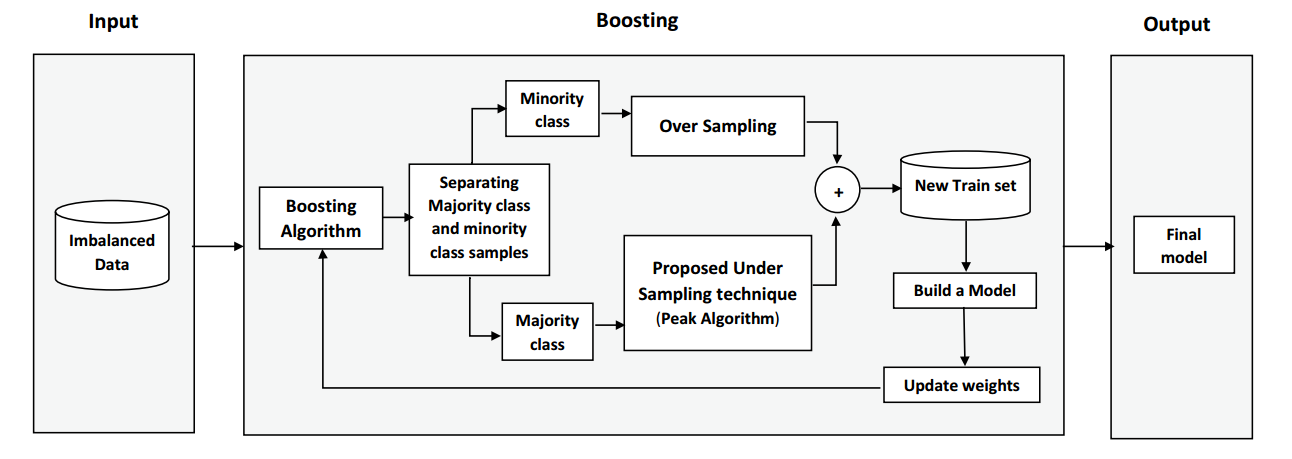
아래 사진은 OUBoost 모델의 아키텍쳐입니다.
Density-peak clustering
이 논문에서 Density-peak clustering(DPC)방법을 사용하여 다수 클래스 데이터를 제거하였는데, DPC가 무엇인지 살펴보겠습니다.
Density-peak clustering (DPC) 알고리즘은 복잡한 구조를 가진 데이터셋에서 클러스터를 식별하기 위해 설계된 클러스터링 알고리즘입니다. 클러스터의 중심을 식별하기 위해 크게 2가지 과정을 거치게 됩니다.
클러스터 중심은 local density가 낮은 샘플들 사이에 위치하며, 더 높은 밀도를 가진 샘플들로부터 상대적으로 멀리 떨어져 있습니다.
샘플 간의 거리와 local density를 결합하여 클러스터를 정의합니다.
여기서 local density, distance라는 2가지 지표가 클러스터를 정의하는데 사용되기 때문에 각각의 정의들을 살펴보겠습니다.
local density($\eta_i$) : 샘플 j주변에 있는 샘플의 개수를 나타냅니다. 이는 반경 $t_r$ 내에 있는 이웃 샘플 수로 정의됩니다.
만약, 샘플 주변에 데이터가 많으면 $\Omega$값은 음수가 되므로 1을 출력하게 됩니다. 즉, 주변에 데이터가 많을수록 $\eta$값이 커집니다. (보통 클러스터 중심 주변에 데이터가 많이 모이게 되죠! 그러니까 $\eta$가 크다는 건 클러스터의 중심일수도 있다는 것입니다!)
최소 거리($\mu_j$) :더 높은 local density를 가진 샘플들로부터의 최소 거리를 계산합니다. 단, local density가 가장 높은 샘플의 경우, 이는 다른 모든 샘플로부터의 최대 거리로 정의됩니다.
$\mu_j = \begin{cases} \max \{d(j, k) \mid k \in S\}, & \text{if } \eta_j \geq \eta_k \text{ for all } k \in S, \\\min \{d(j, k) \mid \eta_j < \eta_k, k \in S\}, & \text{otherwise}.\end{cases}$
위 과정을 통해 각 데이터 포인트에 대해 $\eta_j$, $\mu_j$를 각각 구하여 클러스터의 중심을 결정합니다.
클러스터 중심
각 샘플의 Density와 Distance를 결합하여 새로운 값 $\lambda_j$를 계산합니다.($\lambda_j=\mu_j*\eta_j$)
$\lambda_j$ 값을 내림차순으로 정렬하고, 높은$\lambda_j$ 값을 가진 샘플을 클러스터 중심으로 선택합니다.
클러스터 할당
클러스터 중심이 결정된 이후, 나머지 샘플들은 가장 가까운 클러스터로 할당되게 됩니다.
$\Psi_j = \begin{cases} j, & \text{if } \eta_j \geq \eta_k \text{ for all } k \in S, \\\arg\min \{d(j, k) \mid \eta_j < \eta_k\}, & \text{otherwise}.\end{cases}$
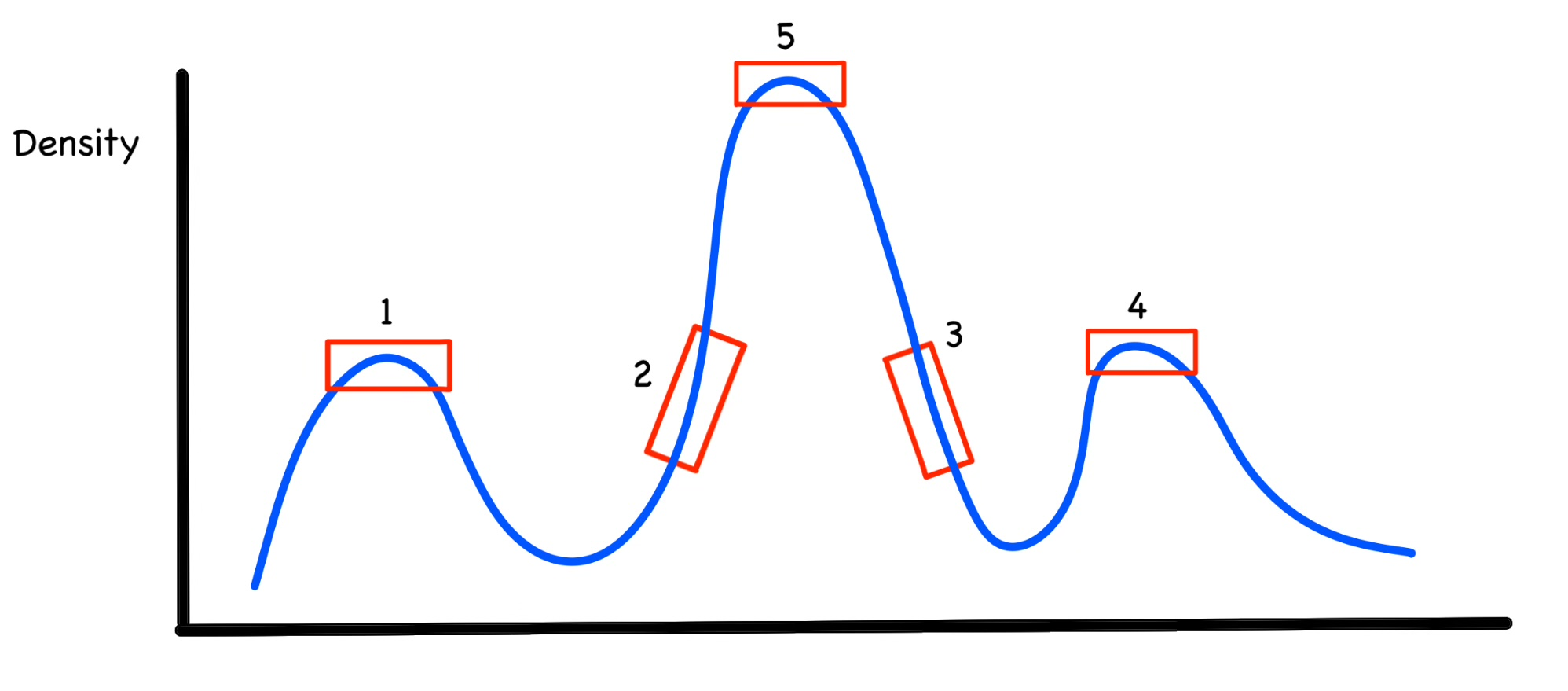
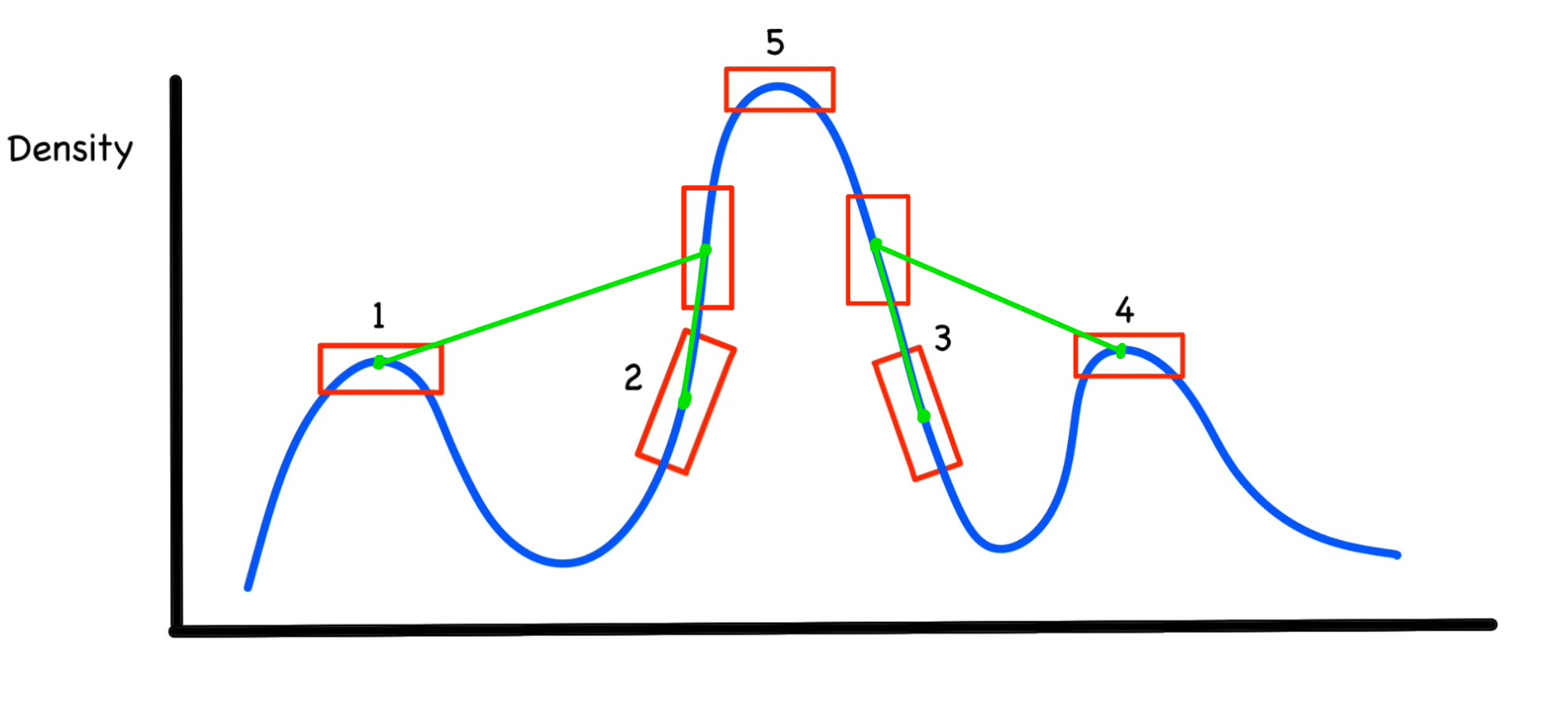
예를 들어 설명해보겠습니다.
위 사진은 $\eta_1=\eta_2=\eta_3=\eta_4$(1~4번까지 같은 density를 가지고, 5는 다른 Density를 가진다)라고 가정하겠습니다.
그렇게 되면 $\lambda$를 계산하기 위해 최소 거리 $\mu$를 계산해야 합니다.(2번,3번 다음의 포인트가 바로 저 네모난 박스라고 하고 거리를 계산하겠습니다. 저 네모난 두 박스는 1,2,3,4보다는 Density가 더 높음)
$\mu_1,\mu_2,\mu_3,\mu_4$를 위의 식에 대입해보면 초록색 선이 거리가 될 것입니다. 1,2,3,4에 대해서 계산해보면 대략 $\mu_1,\mu_4,\mu_2,\mu_3$ 이 순서로 클 것 같습니다.(최소 거리를 계산해야하기 때문에 1,4번은 거리가 멀고 2,3번은 가까운 것을 알 수 있습니다!)
클러스터의 중심을 계산하기 위해 $\lambda$를 계산하게 되면 $\lambda_5,\lambda_1,\lambda_4,\lambda_2,\lambda_3$이 순서로 될 것이고 아마도 더 많은 샘플에서 수행하게되면 클러스터의 중심인 1,3,5만 클러스터링이 될 것 입니다! 그리고 나서 나머지 샘플들은 1,3,5 클러스터에 더 가까운 곳으로 할당이 된다고 생각하시면 됩니다!
Proposed Peak-based Undersampling Algorithm
이제는 DPC 알고리즘을 살펴보았으니 이 알고리즘을 통해 어떻게 Undersampling을 수행했는지 살펴보도록 하겠습니다.
선택 기준은 $L = \{ x_i \mid x_i, x_j \in H \text{ and } d(x_i, x_j) > \theta \}$
선택된 샘플과 Minority class data를 병합해 수정된 데이터셋을 생성합니다. 이 데이터는 여전히 불균형 하지만, 원본 데이터보다는 불균형 비율이 낮습니다.(아마 분류기를 계속 학습하면서 불균형이 완화될 것이라 보입니다.)
Proposed OUBoost Algorithm
이제 저자가 제안한 OUBoost 알고리즘의 전체 흐름을 살펴보겠습니다. 위에는 Undersampling을 위한 방법론을 소개했지만, OUBoost는 소수 클래스를 SMOTE를 사용해 데이터 생성하기 때문에 두 기법을 결합하여 알고리즘이 어떻게 진행되는지 살펴보겠습니다!
데이터셋 분리 및 오버샘플링
원본 데이터셋 S를 소수 클래스와 다수 클래스로 나눕니다.
SMOTE를 사용하여 소수 클래스에서 합성 데이터를 생성하고 이를 원본 데이터셋에 추가합니다.
다수 클래스 언더샘플링
제안된 Peak 기반 언더샘플링 알고리즘을 사용하여 다수 클래스에서 샘플을 선택합니다.
임시 데이터셋 생성
소수 클래스의 모든 샘플과 다수 클래스에서 선택된 샘플을 결합하여 새로운 임시 데이터셋 $S'_t$을 만듭니다.
이 데이터셋은 각 부스팅 단계에서 약한 학습기(weak learner)를 훈련하는 데 사용됩니다.
이때 불균형 비율이 되도록 임시 데이터셋 생성(불균형 비율은 우리가 선택할 수 있음)
만약 불균형 비율이 2:1이라고 하면, 생성된 소수 클래스의 데이터 수와 제거되고 남은 다수 클래스 데이터 수의 비율이 2:1이 되도록 데이터 정제
가중치 업데이트 및 반복
각 단계에서 약한 학습기의 예측 오류율 $\epsilon_t$을 계산합니다.
오류율을 기반으로 가중치 업데이트 매개변수 $\alpha_t$를 계산 $\alpha_t=\frac{\epsilon_t}{1-\epsilon_t}$
이번에는 2020년에 Machine Learning 저널에 게재된 Double random forest 논문에 대해 다뤄보겠습니다.
Double random forest 논문은 Random forest 모델을 보완해서 성능을 조금 더 향상시킨 모델입니다.
생각보다 되게 간단하고 참신한 아이디어 인 것 같아요!
Random forest에서 트리를 생성할 때 부트스트랩을 사용하여 모든 데이터가 사용되지 않는다는 점을 이용하여 Double random forest는 트리를 생성할 때 모든 데이터를 사용해 노드가 다양하게 학습 할 수 있도록 하는것이 이 논문의 Key point라고 보시면 될 것 같습니다. 아래에서 조금 더 자세하게 설명하겠습니다.
Abstract
Random forest는 parallel 앙상블 기법 중 가장 인기있는 방법론입니다. Random forest는 nodesize(hyperparameter) 최소화 하여 트리를 학습시킬 때 예측 성능이 가장 좋다고 합니다.
그러면 저자는 node size를 최소화 하면서 더 큰 트리를 만들 수 있다면 성능이 좋아지지 않을까? 라는 생각에 Double random forest를 제안했습니다.
이 방법론은 처음 트리를 생성할 때 부트스트랩 샘플링(루트 노드에서만)을 수행하는 Random forest와 다르게, 트리를 생성할 때 모든 데이터셋을 학습시키고 각 노드에서 부트스트랩 샘플링을 수행하여 트리의 다양성을 증가시키고자 합니다.
실제로 Double random forest 모델이 Random forest보다 정확도가 높다는 것을 확인하였습니다. 그러면 저자가 제안한 방법론을 pseudo code와 함께 살펴보면서 이해해보도록 하겠습니다.
Double Random Forest(DRF)
이제 Double random forest가 어떻게 작성되어있는지 자세하게 살펴보도록 하겠습니다.
아래 사진은 DRF 알고리즘의 pseudo code입니다.
이해하기 쉽도록 예를 들어서 설명하도록 하겠습니다.
전체 데이터가 100개 있다고 하겠습니다.
Double random forest는 트리를 학습할 때 전체 데이터를 사용합니다. Random forest에서는 부트스트랩 샘플링을 통해서 트리를 학습했습니다.(부트스트랩 샘플링을 통해 중복된 샘플이 뽑힐 수 있으니 데이터가 DRF 보다는 다양하지 않을 수 있습니다.)
DRF는 더 많은 데이터를 사용하기 때문에 RF보다 더 큰 트리를 만들 수 있게 됩니다.(RF보다 더 다양한 데이터가 존재하기 때문에 분할기준이 많아지기 때문)
전체 데이터를 사용하여 루트노드에서 분할하고 난 후 두 개의 자식노드가 생기게 되는데 이때 각 노드에서 부트스트랩 샘플링을 사용해서 데이터를 뽑아 새로운 분할기준을 찾습니다. 이때 두 개의 자식노드에 각 50개씩 분할되었다고 가정하겠습니다.
1번 자식노드 : 50개의 샘플
2번 자식노드 : 50개의 샘플
그러면 각 1번 노드에서 50개의 샘플로 부트스트랩 샘플링을 수행합니다. 부트스트랩으로 뽑힌 샘플들을 사용하여 분할기준을 찾습니다. 부트스트랩 샘플링한 데이터를 통해 분할기준을 찾았다면 원래 50개의 샘플을 분할기준에 따라서 데이터를 나눕니다. 이 과정을 2번노드에도 수행을 합니다.
최적의 분할 과정을 계속해서 수행하는데, 만약 분할된 데이터가 전체 데이터의 10%보다 많지 않으면 부트스트랩 과정을 중단하고 원래 데이터로 분할과정을 수행합니다.
위 과정을 반복하여 트리를 만들어 분류기를 학습하게 됩니다. 그리고 Test data에는 투표 방식을 통해 가장 많이 투표가 된 레이블로 예측을 하게 됩니다.
알고리즘이 Random forest와 크게 다르지 않죠! 전체 데이터셋을 사용하여 더 큰 트리를 만드는 아이디어가 참신하다고 느꼈습니다.
Experimental Results
저자가 만든 DRF 모델과 RF 모델의 성능 차이를 한번 확인해보겠습니다.
mnist데이터를 활용하여 6번의 Test accuracy를 Box plot으로 확인하였고, 결과는 다음과 같습니다.
Box-plot of the test accuracy of RF and DRF using ‘mnist’ data
확실히 루트노드에서 더 많은 데이터를 사용할수록 다양한 트리를 학습할 수 있어서 성능이 좋아진 것을 확인할 수 있습니다.
또한 아래 사진은 200개 트리에서 터미널(최종) 노드의 평균 수와 표준편차를 나타내고 있습니다.
확실히 DRF가 노드의 수가 훨씬 많네요! 위에서 노드 크기가 클수록 예측 성능이 좋다고 하였으니 성능이 더 좋은게 납득이 가네요.
다음은 각 데이터셋에 RF모델과 DRF모델이 유의적으로 차이가 있는지 ANOVA 분석을 수행했습니다.
P-value가 유의수준 5%하에서 매우 작은 값을 가지기 때문에 두 모델은 통계적으로 차이가 있다고 볼 수 있습니다. 즉, DRF가 통계적으로 더 정확하다고 볼 수 있습니다.
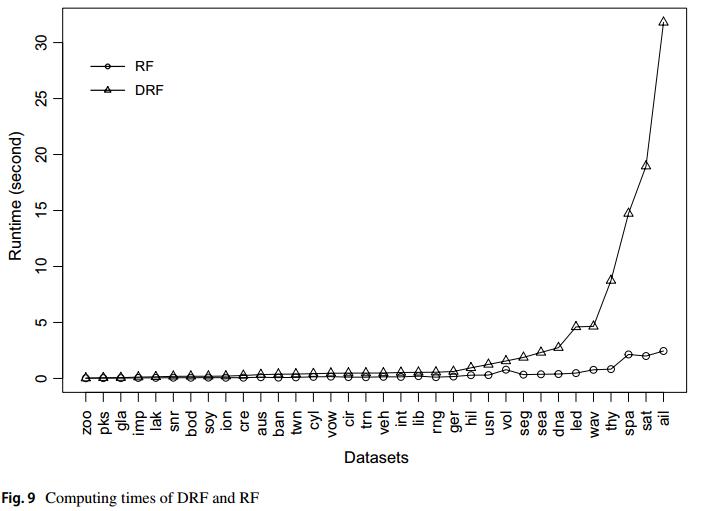
마지막으로 두 모델의 computing times을 비교했습니다.
우측으로 갈수록 데이터셋의 크기가 매우 큰데, 데이터 셋이 클수록 DRF의 Runtime이 확실히 오래걸리는 것을 볼 수 있습니다.
이번 글에서는 2023년 AISTATS에서 발표된 Adversarial Random Forests for Density Estimation and Generative Modeling 논문에 대해 다뤄보도록 하겠습니다.
(랜덤포레스트 모델에 기반해서 데이터 생성할 수 있다는 것이 놀라웠고, 이 분야쪽은 아직 활발히 진행된 것 같지 않아서 깊게 파보면 좋은 모델을 만들어내는데 도움이 될 것 같은 느낌이 든다,,!)
Abstract
저자는 비지도 방식의 Random forest를 활용하여 데이터 생성하고, 밀도 추정에 대한 방법론을 제시하고자 합니다. GAN 모델에 영감을 받아서 생성자와 판별기가 반복적으로 학습하여 트리가 데이터의 구조적 특징을 학습하는 절차를 수행합니다.
이 방법은 최소한의 가정만으로 consistent를 보장한다고 강조하고 있으며, 저자의 방법론은 smooth한 밀도 추정을 제공하여 조금 더 자연스러운 데이터 생성이 가능하다고 합니다.
저자는 Tabular data를 생성하는 딥러닝 모델과 성능을 비교하고 있으며, 실행 속도가 평균적으로 훨씬 빠르다는 점을 강조하고 있습니다.
크게 알고리즘의 형태를 보자면
ARF → FORDE → FORGE 이 순서로 알고리즘이 진행됩니다.
ARF : 분류기 학습
FORDE : ARF에서 학습한 분류기를 통해 각 리프노드에서의 파라미터 추정
FORGE : 추정된 파라미터를 통해 데이터 생성
이제는 ARF 알고리즘에 대해 설명할 것입니다.(분류기 학습하는데 중점을 둔 알고리즘에 대해서!)
ADVERSARIAL RANDOM FORESTS
이제 저자가 제안한 방법론에 대해서 자세하게 다뤄보겠습니다.
ARF(Adversarial Random Forest)는 URF(Unsupervised Random Forest)의 재귀적 변형으로, 각 리프 노드에서 데이터가 서로 독립적인 상태(jointly independent)가 되도록 하는 것이 목표입니다. 아마도 변수별로 독립적인 패턴을 파악하여 간결하고 일반화된 모델을 만드는 데 도움이 될 것 같습니다.
(다음 글에서 ARF 알고리즘의 pseudo code를 직접 뜯어보면서 더 자세하게 다룰 것입니다. 아래는 알고리즘의 흐름)
초기 단계: 먼저 기존의 URF를 합성 데이터 $\tilde{X}^{(0)}$로 학습하여 분류기 $f^{(0)}$을 생성합니다. 만약 분류기의 정확도가 50%이상이라면(생성데이터와 원본데이터의 구분 확률) 리프노드의 coverage를 계산하게 됩니다. 이때 coverage는 원본데이터에 대해서 계산하게 됩니다.(coverage라는건 원본데이터가 각 리프노드에 들어간 비율을 말합니다.) 각 리프 노드의 커버리지를 계산한 후, 이 비율에 따라 리프 노드를 무작위로 선택하고, 그 안의 마진으로부터 새로운 합성 데이터셋 $\tilde{X}^{(1)}$을 생성합니다. (커버리지가 높을수록 그 리프에서의 데이터 생성 개수는 많아짐) 생성된 합성 데이터 $\tilde{X}^{(1)}$과 원본 데이터 $X$를 구분하는 새로운 분류기 $f^{(1)}$을 학습합니다.(ARF 알고리즘에서 분류기를 학습하고 나서 그 분류기를 통해 밀도추정(FORDE)과 데이터 생성(FORGE)하는 것임! ARF는 분류기 학습에 중점을 두는 것이지 데이터 생성하는것이 목적이 아닌것을 알아두자!)
새로운 분류기의 OOB(Out-of-Bag) 정확도가 충분히 낮아지면 ARF가 수렴한 것으로 간주하고, $f^{(1)}$를 최종 모델로 사용합니다. 그렇지 않다면, 위의 과정을 반복하여 새로운 합성 데이터셋을 생성하고 분류기를 학습합니다. → 수렴할때까지!
수렴의 의미
수렴한다는 것은 ARF의 분류기가 더 이상 합성 데이터와 원본 데이터를 구분할 수 없게 되었다는 것을 의미합니다. 즉, 합성 데이터가 원본 데이터와 매우 유사해져서 분류기의 정확도가 대략 50%에 도달한 상태를 말합니다. 이때를 수렴한다고 말하고 있습니다.
OOB(Out-of-Bag) 정확도란?
랜덤 포레스트(Random Forest)에서 모델 성능을 평가할 때 사용하는 방법이며, 선택되지 않은 샘플을 활용하여 모델의 성능을 측정합니다. (부트스트랩 샘플링을 사용하면 데이터의 63%정도가 각 트리의 학습에 사용되고, 나머지 37%는 사용되지 않습니다. 각 트리에서 n개의 샘플을 복원추출로 뽑는다고 생각하면 한개의 샘플이 뽑히지 않을 확률은 (1-$\frac{1}{n}$)입니다. 트리가 무한대로 증가하면 $\lim\limits_{n\rightarrow \infin}(1-\frac{1}{n})^n$=$e^{-1}$ ≈ 0.3678794 )
각 트리에 대해 OOB 샘플을 사용해 정확도를 측정하고, 모든 트리의 결과를 평균하여 최종 OOB 정확도를 계산합니다. → 충분히 낮다면 ARF수렴
ARF(Adversarial Random Forest)는 GAN과 유사한 구조를 가지고 있지만 몇 가지 중요한 차이점이 있습니다.
유사점
ARF에서의 "생성자"는 marginal distribution에서 샘플링하여 데이터를 생성하는 역할을 하고, "판별자"는 랜덤 포레스트 분류기입니다. 이 둘은 서로 번갈아 가며 레이블 불확실성을 높이고 낮추는 제로섬 게임 형태로 작동합니다.
차이점
파라미터 공유: ARF에서는 생성자와 판별자가 동일한 파라미터를 공유합니다. GAN에서는 생성자와 판별자가 뉴럴네트워크를 통해 파라미터를 학습했지만, ARF에서 생성자는 스스로 학습하지 않고 판별자가 학습한 정보를 활용하는 방식입니다.
ARF모델에서 합성 데이터는 원본데이터들을 이용하여 복원추출한 데이터입니다. 즉, 새롭게 생성한 데이터가 아닌 것입니다! → ARF 알고리즘에서는 데이터를 독립적으로 만드는 leaf를 학습하는데 중점을 두고있습니다. 새로운 데이터를 생성하는 것은 FORDE를 통해 분포에 대한 parameter를 학습하고 FORGE에서 새로운 데이터를 생성합니다!
ARF는 한 번의 반복만으로도 데이터의 독립성을 유도할 수도 있다고 합니다.
위에서는 ARF 모델에 대한 흐름을 설명하였고 이제는 각 리프노드에서 변수들 간의 독립성을 만족시키기 위한 조건에 대해 살펴보겠습니다! (가장 중요한 부분! 변수간 독립이 만족하지 못하면 의미가 없음)
ARF(Adversarial Random Forest)가 데이터의 독립성을 확보하고 수렴하는 데 필요한 조건과 가정에 대해 설명하겠습니다.
Local Independence Criterion
목표: ARF의 목표는 각 트리의 모든 리프 노드에서 데이터가 독립적으로 분포하도록 분할을 수행하는 것입니다. 모든 트리 b, 리프 노드 $\ell$, 그리고 샘플 x에 대해 다음을 만족하는 분할 세트 Θ를 찾는 것입니다. $p(x|\theta^\ell_b)=\prod^d_{j=1}p(x_j|\theta^\ell_b)$. 즉, 각 리프 노드에서 데이터의 joint probability가 각 변수들의 곱으로 표현될 수 있음을 의미하며 각 노드 내에서 변수들이 독립이라는 것을 말할 수 있습니다.
Assumption 1 : 특성 도메인 가정
특성 공간 제한: 특성 공간이 $X=[0,1]^d$로 제한되어 있으며, 이 범위 내에서 joint density p가 0과 ∞ 사이에서 안정적으로 유지된다는 가정입니다. 이는 데이터가 모든 특성에 대해 정상적인 분포를 가지고 있고, 특성 값들이 정해진 범위 내에서 벗어나지 않음을 의미합니다.
Assumption 2 : Lipschitz 연속성 가정
Lipschitz 연속성: 각 라운드마다 목표 함수 P(Y=1∣x)가 Lipschitz 연속성을 만족해야 한다는 가정입니다.
Lipschitz 연속성은 함수의 변화 속도가 특정한 상수(즉, Lipschitz 상수)로 제한된다는 것을 의미합니다. Lipschitz 상수가 매 라운드마다 바뀔 수 있지만, 이 값이 $\frac{1}{max_{\ell,b}(diam(X^\ell_b))}$
보다 빠르게 증가하지 않는다는 제한을 둡니다.
이 가정은 데이터 분포가 과도하게 변화하지 않도록 하여 안정적인 학습을 보장합니다.
Assumption 3 : 트리 구성 및 학습에 관한 조건
이 가정은 ARF에서 사용되는 트리 구조에 대한 여러 가지 조건을 설정합니다.
(i) 트레이닝 데이터 분할: 각 트리를 학습할 때, 데이터를 두 부분으로 나눕니다:
하나는 분할 기준을 학습하기 위한 부분이고,
다른 하나는 리프 노드에 레이블을 할당하기 위한 부분입니다.
(ii) 트리의 성장 방식:
각 트리는 부트스트랩 샘플링이 아닌 subsamples(중복 허용x)를 사용해 학습됩니다.
부트스트랩 샘플링으로 학습되면 과적합이 발생할 수도 있기 때문!
이라고 하는데, 실제 코드 뜯어보니 부트스트랩 샘플링으로 트리를 학습하는 것 같은데,,, 혹시나 보신 분이 있다면 의견 부탁드립니다. (_ _)
트리 학습할 때 subsampling하려면 ranger함수에서 수정을 해야할 듯 함(뇌피셜)
subsamples의 크기 $n_b$(트리b에서 학습에 사용되는 데이터 수)는 n보다 작아야 합니다. ($n_b$→∞, $n_b$/**$n$**→0 as **$n$**→ ∞).
(iii) 분할 확률:
각 내부 노드에서 특정 특성 $X_j$를 분할할 확률은 최소 π>0으로 제한됩니다.
예를 들어 키와 몸무게에 대한 변수가 있다면, 처음 루트노드에서 키를 선택할지 몸무게를 선택할지에 대한 확률을 부여해줘야 합니다. 즉, 특정 특성에만 의존하지 않도록 합니다.
(iv) 분할의 균형성:
각 분할에서 두 자식 노드에 들어가는 데이터 비율은 최소한 γ∈(0,0.5]이어야 합니다.
이 부분은 자식노드에 최소한의 비율을 보장하기 위해서 설정한 것입니다. 만약 설정하지 않게되면 두개의 자식노드의 비율이 0.99, 0.01 이렇게 분할이 되는 상황이 발생할 수도 있기 때문입니다.
(v) 리프 노드의 개수:
각 트리 b에 대해 리프 노드의 총 개수 $L_b$는 ∞로 향해야 하지만, 전체 데이터 수 n에 비해 작아야 합니다. ($L_b$→∞, $L_b$/**$n$**→0 as **$n$**→ ∞).
(vi) 소프트 레이블:
각 노드의 예측 확률을 투표가 아닌 평균을 통해 결정한다는 의미입니다.
ARF는 특성 독립성을 확보하고 데이터를 효과적으로 분할하기 위해 위의 가정들(A1~A3)을 만족하는 환경에서 작동합니다. 이러한 가정들은 ARF가 수렴하고, 리프 노드에서 데이터의 독립성을 확보하여 밀도 추정 및 데이터 생성에 적합한 모델을 학습하는 데 필수적인 역할을 합니다.
데이터의 변수들이 독립이 되는것을 아주 강조하는걸 보니 독립이냐 아니냐에 따라 모델의 성능을 좌지우지하는 것 같다는 생각이 드네요(어쩌면 독립이 아니라면 성능이 너무 낮게 나올수도)
Density Estimation and Data Synthesis
ARF에서 변수별 독립을 만족시키기 위한 가정들을 살펴보았고, ARF알고리즘을 통해 분류기를 생성하고 그 분류기를 활용하여 Density 추정과 데이터 생성하는 파트에 대해 설명하겠습니다.
ARF(Adversarial Random Forest)는 두 가지 알고리즘인 FORDE(FORests for Density Estimation)와 FORGE(FORests for GEnerative modeling)의 기반이 됩니다. [위에서 말했듯이 ARF알고리즘을 통해 분류기 생성 → 그 분류기를 이용해 density 추정(FORDE) → density를 통해 각 변수별 데이터 생성(FORGE)]
이 두 알고리즘에서 local independence criterion을 활용해 각 리프 노드 내에서 다변량 밀도 추정 대신 d개의 개별 단변량 밀도 추정기를 실행합니다. 이는 고차원 데이터에서 발생하는 차원의 저주를 피할 수 있기 때문에 훨씬 효율적입니다. 실제로 고차원 데이터에서 전통적인 커널 밀도 추정(KDE)은 차원의 제약으로 인해 잘 작동하지 않지만, ARF는 독립성을 확보하는 분할을 학습함으로써 밀도 추정과 데이터 생성에 더 효과적이고 효율적으로 대응할 수 있습니다.
여기서 차원의 저주를 피할 수 있다고 말하는 이유는, ARF가 각 변수들 간의 독립성을 확보함으로써 각 변수에 대해 개별적으로 밀도 추정을 할 수 있기 때문입니다. 일반적으로 다변량 밀도 추정은 고차원 데이터에서 모든 특성 간의 결합 분포를 학습해야 하기 때문에, 차원의 저주(curse of dimensionality)라는 문제에 직면하게 됩니다. 이는 데이터의 차원이 높아질수록 추정해야 할 분포의 복잡성이 기하급수적으로 증가하기 때문입니다. 반면에, ARF의 경우 local independence criterion(각 변수들 간 독립!)에 따라 리프 노드 내에서 각 특성들이 독립적으로 분포하므로, 각 변수에 대해 단변량 밀도 추정(univariate density estimation)을 수행할 수 있습니다. 이를 통해 다변량 밀도 추정에서 발생하는 차원의 저주 문제를 효과적으로 피할 수 있게 됩니다.
ARF를 기반으로 FORDE와 FORGE 알고리즘이 다음과 같이 진행됩니다.
FORDE
각 트리 b에 대해 분할 기준 $\theta^\ell_b$와 각 리프 노드 $\ell$의 경험적 커버리지 $q(\theta^\ell_b)$를 기록합니다. 이것들을 리프 노드의 파라미터라고 부릅니다.
그런 다음 각 리프 노드에 대해, 원래 데이터의 각 특성 $X_j$에 대해 독립적으로 분포 파라미터 $\psi^\ell_{b,j}$를 추정합니다.
예를 들어, 연속형 데이터의 경우 커널 밀도 추정(KDE)의 대역폭이나 MLE를 활용해 추정합니다.
각 변수에 대한 파라미터 $\psi^\ell_{b,j}$학습
연속형 데이터의 경우 MLE를 사용하여 truncated Gaussian mixture model을 구현하고, 범주형 변수에 대해서는 베이지안 추론을 사용합니다. 이는 리프 노드에서 관찰되지 않은 값에 대해 극단적인 확률을 피하면서 리프 노드의 지원(support) 내에 있는 값을 반영하기 위함입니다.
FORGE
트리 선택: 전체 트리 집합 B에서 트리 b를 균등하게 무작위로 선택하고, 해당 트리에서 리프 노드 $\ell$)를 커버리지 확률 $q(\theta^\ell_b)$ 에 따라 선택합니다. 이는 ARF 알고리즘의 재귀적 반복에서 합성 데이터를 생성하는 방식과 동일합니다.
특성 샘플링: 각 특성 $X_j$에 대해, $\psi^\ell_{b,j}$에 의해 매개변수화된 밀도 또는 질량 함수에 따라 데이터를 샘플링합니다.
이렇게 데이터 생성을 했으니까 데이터 생성을 잘 했는지 확인할 필요가 있죠! 그러기 위해서 추정된 밀도와 실제 밀도를 비교합니다!
추정된 밀도 함수 $q(x)$는 다음과 같이 표현됩니다 $q(x)=\frac{1}{B}\sum\limits_{\ell,b:x\in X^\ell_b}q(\theta^\ell_b)\prod\limits_{j=1}^dq(x_j;\psi^\ell_{b,j}).$
여기서 B는 전체 트리의 수를 나타내고, 분포는 해당 리프 노드에 대한 커버리지 $q(\theta^\ell_b)$에 가중치가 부여된 모든 리프 노드의 평균값으로 나타납니다.
이때 $q(x_j;\psi^\ell_{b,j})$는 각 특성 $x_j$에 대한 밀도 함수입니다.($\psi^\ell_{b,j}$를 distribution의 parameter로 설정)
**실제 밀도 함수 $p(x)$**는 다음과 같습니다
이 경우 역시 커버리지 확률$p(\theta^\ell_b)$로 가중치가 부여된 각 리프 노드의 밀도로 구성되어 있습니다.
Error of Density $\epsilon_2:=\epsilon_2(\ell,b,x):=\prod\limits_{j=1}^d p(x_j|\theta^\ell_b)-\prod\limits_{j=1}^dq(x_j;\psi^\ell_{b,j})$
정의: 리프 노드 $\ell$, 트리 b, 샘플 x에 대해, 실제 조건부 밀도 $\prod\limits_{j=1}^d p(x_j|\theta^\ell_b)$와 추정된 조건부 밀도 $\prod\limits_{j=1}^dq(x_j;\psi^\ell_{b,j})$의 차이입니다.
의미: 각 리프 노드 내에서 특성별로 독립적으로 추정된 밀도가 실제 밀도와 얼마나 다른지를 나타내는 오류입니다.
Error of Convergence $\epsilon_3:=\epsilon_3(\ell,b,x):=p(x|\theta^\ell_b)-\prod\limits_{j=1}^d p(x_j|\theta^\ell_b)$
정의: 리프 노드 $\ell$, 트리 b, 샘플 x에 대해, 실제 조건부 밀도 $p(x|\theta^\ell_b)$와 특성별 조건부 밀도의 곱 $\prod\limits_{j=1}^d p(x_j|\theta^\ell_b)$의 차이입니다.
의미: 실제 조건부 밀도가 각 특성의 독립적 밀도의 곱과 얼마나 다른지를 나타내는 오류입니다. 이는 실제 데이터가 특성 간에 종속성을 가질 경우 발생할 수 있습니다.
$\epsilon_{2,3}$ 리프 노드 $\ell$, 트리 b, 그리고 샘플 x에 따라 달라지는 랜덤 변수입니다.
이러한 가정들과 오류 정의를 통해 ARF는 consistency을 보장하고, 효과적인 데이터 생성 및 분포 학습을 수행할 수 있습니다.
Experiments
위 그림은 ARF 모델을 사용하여 데이터 생성하였습니다. ARF모델이 생각보다 데이터 생성을 잘 하고 있는 것을 볼 수 있습니다.
또한 ARF를 이용해 데이터 생성한 모델과 다른 딥러닝 모델의 성능을 비교해 보았습니다. 어떤 경우에는 FORGE가 성능이 높고 다른 데이터셋에선 다른 딥러닝의 모델이 성능이 높지만, ARF의 모델이 성능이 뒤쳐지지 않을뿐 아니라 가장 빠르게 학습을 할 수 있다는 것입니다. 시간측면에서는 월등히 앞서는 것을 볼 수 있습니다.
다음 글에서 ARF, FORDE, FORGE 알고리즘의 pseudo code를 깃허브에 제공되어있는 R코드와 함께 살펴보면서 각 단계별로 모델이 어떤 흐름으로 진행되는지 확인해보도록 하겠습니다.
이번 글에서는 latent space에서 Minority class를 oversampling하여 불균형 문제를 해결할 수 있는 논문을 다뤄보겠습니다.
Abstract
이 논문은 데이터 불균형의 문제를 해결하기 위해 Minority class의 데이터를 latent space에서 Oversampling하여 불균형 문제를 해결하고자 합니다. 이때 Minority class의 데이터는 RAE(Regularized Auto Encoder)를 통해 latent space로 보내지게 됩니다.
latent space에서 Oversampling을 수행하기 때문에 좋은 latent space(데이터를 잘 표현해주는 잠재 공간)를 학습해야 합니다. 그러기 위해서 저자는 Auto-Encoder의 구조를 사용해 조건부 데이터 우도(conditional data likelihood)를 최대화함으로써 latent space를 효과적으로 학습합니다. (특히, latent 샘플들의 convex combination을 사용해 새로운 데이터를 생성하면서도 동일한 클래스의 identity를 보존해야 한다고 합니다. 즉, convex combination을 통해 생성된 데이터가 같은 클래스를 가져야 한다는 뜻 )
또한 저자는 SMOTE와 같은 naive한 oversampling방법과 비교하여 low variance risk estimate을 달성했다고 합니다. 결과적으로 이 방법은 Minority class를 oversampling하는데 효과적이며 불균형 데이터를 해결하는데 도움을 준다고 합니다.
이제부터 차근차근 하나씩 살펴보도록 하겠습니다.
Proposed Method
Class Preserving Oversampling
여기서는 latent space의 분포인 q(z)가 클래스 보존 방식으로 학습되는 것이 핵심입니다.
이때 latent space에서 convex combination을 통해 새로운 샘플을 생성하고자 합니다.
예를 들어 $z_i, i=1,2,...,t$ 이때 $z_i$는 latent vector라고 하고 그에 상응하는 데이터포인트 $x_i, i=1,2,...,t$가 모두 같은 클래스를 갖고있다고 하면 이때 새로운 latent point $z'$은 다음과 같이 얻어집니다.
하지만, 단순히 이렇게 convex combination을 통해 생성된 새로운 데이터는 클래스 보존을 하지 못할수도 있습니다. (각 클래스의 latent space가 겹치는 영역이 존재하게 되면 convex combination을 통해서 생성된 데이터가 클래스 보존을 못할수도 있다는 얘기인 듯 합니다.)
그래서 클래스 보존에 대한 문제를 해결하기 위해서는 두가지를 말하고 있습니다.
class-conditional latent space를 학습해야 합니다.이때 각 클래스별로 class-conditional latent density가 겹치지 않아야 한다고 합니다. 즉,각 클래스마다 서로 다른 영역을 가진 latent space를 가져야 합니다.
각 클래스들은 latent space에서 linearly separable해야 됩니다.
각 클래스 i에 속하는 샘플들의 집합 $R_i=\{x|h(z)=i\}$는, linear classifier h(z)에 의해 클래스 레이블 i를 갖는 샘플들입니다. 이때 $q(z|x\in R_i)$는 클래스 i에 대한latent 분포를 의미합니다. 그리고 두 클래스 i, j에 대한 latent 분포의 support가 겹치지 않도록 학습해야 합니다.
즉, $Supp(q(z|x\in R_i)) \cap Supp(q(z|x\in R_j)) =\varnothing$식을 만족해야 합니다.latent space 학습과 linear classifier 학습을 함께 진행하여 oversampling된 벡터도 원래 클래스에 속하도록 만드는 방식을 다루고 있습니다.
위 두가지인 latent space 학습과linear classifier 학습을 함께 진행하여 oversampling된 벡터도 원래 클래스에 속하도록 만드는 방식을 다루고 있습니다.
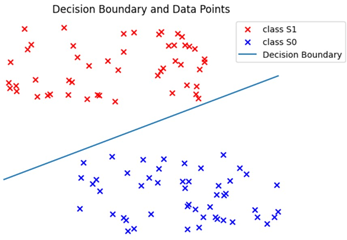
여기서 linear classifier는 latent space에서 벡터들이 같은 클래스에 속하는지 확인하는 역할입니다. 예를 들어, 클래스 S1에 속하는 여러 샘플의 latent 벡터를 결합했을 때, 새로운 벡터도클래스 S1로 분류되도록linear classifier가 학습됩니다.(위 사진처럼 linear classifier가 linearly separable하다면 S1의 latent vector들의 convex combination도 S1의 Decision Boundary에 속할 것이라는 겁니다.)
위 사진을 보면1. class-conditional latent space를 학습하였고(겹치지 않는 latent space), 2. latent space에서 linearly separable함!(저런 상태를 원함)
Regularized Autoencoders with class preserving latent space
이 부분은클래스 정보를 유지하면서 오버샘플링을 수행하기 위한latent space 학습 방법을 설명합니다. 저자는degenerate representation을 방지하기 위해클래스 보존 제약을 적용하여 **조건부 데이터 우도(conditional data likelihood)**를 최대화하면서latent space를 학습합니다.
이를 위해Regularized Auto-Encoder구조를 활용하여 클래스 정보를 보존한 채latent space를 학습합니다.
Degenerate Representation이란?
Degenerate representation이란, 학습된 모델이 입력 데이터를 지나치게 단순화하거나 압축하여중복되거나 정보가 손실된 표현을 만들어내는 상황을 의미합니다.latent space에서 서로 다른 데이터들이 거의 동일한 벡터로 매핑되거나, 각 데이터의 고유한 특성들이 사라져 버리는 것을 말합니다.
만약 단일 latent vector로 매핑이 된다면 (위에서 언급했던Class Preserving Oversampling) latent space가 클래스를 보존할 수는 있겠지만, 다양한 데이터를 생성할 수 없게되어oversampling의 의미가 없어진다고 볼 수 있습니다.
이 문제를 해결하기 위해서 $p(x|z')$(conditional data-likelihood)를 최대화 하여 latent space를 학습한다고 합니다. 이때 클래스 보존 제약을 추가하여각 클래스 간의 latent space가 겹치지 않아야 합니다!
Encoder-Decoder 구조
Encoder: 입력 데이터(x)를latent space로 축소합니다. 이때 조건부 잠재 분포(conditional latent distribution)를 학습하여, 입력 데이터가 어떤 클래스에 속하는지 반영한 채로 latent 벡터 z로 변환합니다. 이는 $q_\varphi(z|x)$로 표현됩니다. ( $\varphi$는 parameter)
Decoder: 학습된 latent 벡터 $z'$(이 $z'$은 latent vector들 간의 convex combination)를 기반으로, 원래 데이터를 복원하는 네트워크입니다. 이는 $p_\theta(x|z')$로 표현되며, oversampled된 데이터가 복원될 때도 클래스 정보가 잘 유지될 수 있도록 학습됩니다.
조건부 데이터 우도(Conditional Data Likelihood)
Decoder네트워크에서 Conditional Data Likelihood( $p(x|z')$ )를 최대화하여, latent space에서 학습된 데이터가 원본 데이터를 잘 복원할 수 있도록 합니다. 이 과정을 통해 latent space가 데이터를 잘 표현할 수 있는 구조로 학습됩니다.
여기서 클래스 보존 제약으로 linear classifier인 $h_w(z)$를 사용합니다. 이 linear classifier는 latent space에서 클래스 간 겹침이 없도록 학습합니다.
이제 최적화 문제를 해결하는데클래스 보존을 유지하면서latent space를 학습하고자 합니다!
conditional data likelihood를 최대화 하여 latent space에서 얻어진 벡터 z가 degenerate representation을 피하면서 원본 데이터를 잘 표현하도록 합니다.이때 제약조건으로 latent space에서 각 클래스간 겹침이 발생하지 않아야 합니다. ($Supp(q(z|x\in R_i)) \cap Supp(q(z|x\in R_j)) =\varnothing$)
conditional data likelihood를 최대화 하여 latent space에서 얻어진 벡터 z가 degenerate representation을 피하면서 원본 데이터를 잘 표현하도록 합니다.이때 제약조건으로 latent space에서 각 클래스간 겹침이 발생하지 않아야 합니다. ($Supp(q(z|x\in R_i)) \cap Supp(q(z|x\in R_j)) =\varnothing$)
세가지 네트워크인 Encoder, Decoder, Classifier는 동시에 학습됩니다. 학습과정에서 convex combination을 통해 oversampling이 진행되게 됩니다. 학습이 완료되면 oversampling된 데이터의 클래스를 보존할 수 있게 되며 성능이 향상될 것입니다.
Implementation Details
제안된 모델은 Encoder network($E_\varphi$), Decoder network($D_\theta$), 그리고 latent space는 linear classifier($L_\omega$)로 구성되어있습니다. (이때 linear classifier는 선형적으로 클래스들을 분리할 수 있도록 제약 걸었음)
이제 저자가 제안한 모델의 아키텍처를 살펴보겠습니다.
Figure 1: Architecture of the proposed methodology. It is a regularized autoencoder, where thelatent space is regularized using a linear classifierto facilitate distance metric free class preserving oversampling of the minority classes. The decoder network maximizes the conditional data likelihood to avoid degeneracy in the latent space.
Mixer Network
위 그림을 보시면 $M_\xi$가 존재하는데 이는Mixer network라고 불리며 여러 latent vector $z_i$들을 입력으로 받아 oversampling을 위한 mixing coefficient $\alpha$를 생성합니다. Mixer network는softmax 층을 통해$\alpha$를 생성합니다.
Mixer network는 linear classifier가 분류하기 어려운 샘플을 생성하도록 학습되며 그러기 위해서는 cross-entropy loss를 최소화하도록 학습됩니다. 즉, 새롭게 생성된 $z'$이 linear classifier에 의해 올바르게 분류되지 못하도록 합니다.
Loss는 oversampled된 샘플 $z'$가 원래 $z_i$들과 다른 레이블을 가지도록 설정됩니다. 즉, linear classifier가 이 oversampled된 샘플을 정확하게 분류하지 못하게 하는 것을 목표로 학습됩니다.
아래는 mixer network의 loss입니다.
C : 전체 클래스의 수
$y_j^{(k)}$ : 클래스 j에 대한 one-hot 인코딩된 레이블입니다. 데이터가 클래스 j에 속하면 1, 아니면 0
$\hat{y}'(k)=L_\omega(z')^{(k)}$: linear classifier $L_{\omega}$가 oversampled된 latent vector $z'$에 대해 예측한 클래스 j의 확률입니다.
이 loss function의 목적은 mixer network가 만든 oversampled된 latent vector $z'$이 linear classifier $L_{\omega}$에 의해 잘못 분류되도록 유도하는 것입니다.
cross entropy loss를 최소화한다는 것에 직관적으로 이해가 되지 않을 수 있어 예를 들어 설명하겠습니다.
Class : 개, 고양이, 토끼 이렇게 3개의 클래스가 있다고 하겠습니다.
원래 클래스는 개라고 설정하겠습니다.(i=개) 그리고 개의 latent vector들의 convex combination으로 새롭게 생성된 $z'$은 개이지만, 임의로 고양이로 설정하겠습니다.(j=고양이)
그러면 분류기는 $z'$에 대해 당연히 개라고 분류할 확률이 높겠죠? (개의 latent vector들로 convex combination을 수행했으므로!)
loss는 0.7985가 되었습니다. 즉, cross entropy를 최소화 하려면 분류기가 고양이의 확률을 높이는 것입니다. 결국 $z'$에 대해서 분류기는 개와 고양이 중에 분류하기 어려운 샘플이 만들어 지겠죠? 그것이 이 Mixer network가 원하는 것입니다!(분류기가 분류하는데 어려움을 겪게되는 샘플을 생성하는 것)
$z'$은 강아지 label을 갖지만, 고양이와 강아지를 확실하게 분류하기 어려운 샘플을 만드는 것이지요!
이를 통해, Mixer 네트워크는challenging samples를 생성하여 모델의robustness를 향상시키고, latent space에서 클래스 보존과 다양성을 동시에 유지하게 됩니다. (Mixer network의 역할은 $\alpha$를 다양하게 설정하여 동일 클래스 내에서 다양한 샘플을 생성하는 것입니다. 논문에서 각 클래스 간의 latent space가 겹치지 않도록 설계되었기 때문에, $\alpha$를 통해 어려운 샘플을 만들어도 클래스는 변하지 않습니다. 따라서, Mixer network는 클래스 내에서의 데이터 다양성을 높이기 위한 과정으로 이해할 수 있을 것 같습니다!)
이제 Mixer network를 살펴보았으니 Encoder, Decoder, linear classifier부분의 loss를 살펴보겠습니다.
Decoder
Decoder부분에서는 $p_\theta(x|z')$를 최대화 합니다. 저자는 adversarial loss를 사용하여 decoder가 생성한 데이터의 분포와 기존의 데이터의 분포를 일치시키기 위함입니다. 여기서 WGAN-GP를 사용하여 안정적이고 수렴이 잘 되도록 합니다. 또한 Critic network를 도입하는데, 이는 생성된 샘플과 실제 데이터 샘플 간의 차이를 줄이고, 그래디언트 패널티를 통해 안정적인 학습을 보장합니다!
(아마 여기서 WGAN-GP를 사용한 이유는 만약 분포끼리의 겹침이 없으면Kullback-Leibler Divergence & Jensen-Shannon Divergence는 안정적으로 학습이 어려워 wasserstein distance를 사용해 분포간 거리를 일치시키는 것 같습니다.)
Decoder 손실함수
의미: 디코더는 Critic 네트워크의 출력을 최대화하여, 생성된 샘플이 실제 데이터와 유사한 분포를 갖도록 유도합니다.
Critic 손실함수
의미: Critic은 생성된 샘플과 실제 데이터 샘플 간의 차이를 줄이고, 그래디언트 패널티를 통해 안정적인 학습을 보장합니다.
디코더 단독으로는 생성된 샘플이 실제 데이터 분포와얼마나 유사한지를 직접적으로 측정하기 어렵습니다. 단순한 재구성 손실(reconstruction loss)이나 픽셀 단위의 손실은 샘플의 질적 유사성을 제대로 반영하지 못할 수 있습니다.
Critic network는 생성된 샘플과 실제 샘플 간의 분포적 차이를 측정하여, Decoder가 보다 정교하게 학습할 수 있도록 피드백을 제공합니다.
그리고 여기서 sample-by-sample 간의 매치가 아니라 하는데, 그 이유는 생성된 데이터는 기존의 데이터에 존재하지 않기때문에 샘플들 간의 매치를 보는것이 아닌 생성된 데이터의 분포와 기존의 데이터의 분포 차이를 보는거라고 하고 있습니다.
Linear Classifier
다음은 linear Classifier에 대해서 설명하겠습니다.
여기서는 categorical crossentropy loss terms을 사용하게 되는데, 이때 사용되는 데이터는 (i=개의 개수와 새롭게 생성된 $z'$까지 총 t+1개의 데이터에 대해서 loss를 구하게 됩니다.)
아래는 classifier에 대한 loss function입니다.
여기서 $z'$ 외에는 앞에 텀에서 계산이 되고, 뒤에 텀에서 $z'$에 대한 loss가 계산이 되는데, 이번에는 분류기가 $z'$에 대해서 강아지로 분류할 수 있도록 업데이트 됩니다.(앞에서는 일부러 $z'$을 고양이로 설정해서 $\alpha$를 만들었지만, 얘는 결국엔 강아지에 대한 데이터입니다. 그렇기 때문에 여기 linear classifier에서는 $z'$에 대해서 강아지라고 제대로 분류할 수 있도록 손실함수를 업데이트 해야합니다!)
Encoder
Encoder network에서 input data를 latent space로 보낼때 중요한 정보를 담고잇도록 해야합니다.
아래는 encoder에 대한 loss function입니다.
encoder손실에는분류 손실과,평균 절대 오차 손실로 구성되어있습니다.
분류 손실을 학습하여 latent space에서의 vector들이 중요한 정보를 담을 수 있도록 합니다.
평균 절대 오차 손실에서는 input data랑 input data를 Encoder를 통해 잠재벡터로 변환 후 다시 디코더를 통해 복원한 데이터 간의 차이를 확인해 재구성이 잘 되도록 합니다. (또한 재구성이 잘 됐다는건, latent space에서 latent vector가 중요한 정보를 담고있었다고 해석할 수 있습니다.)
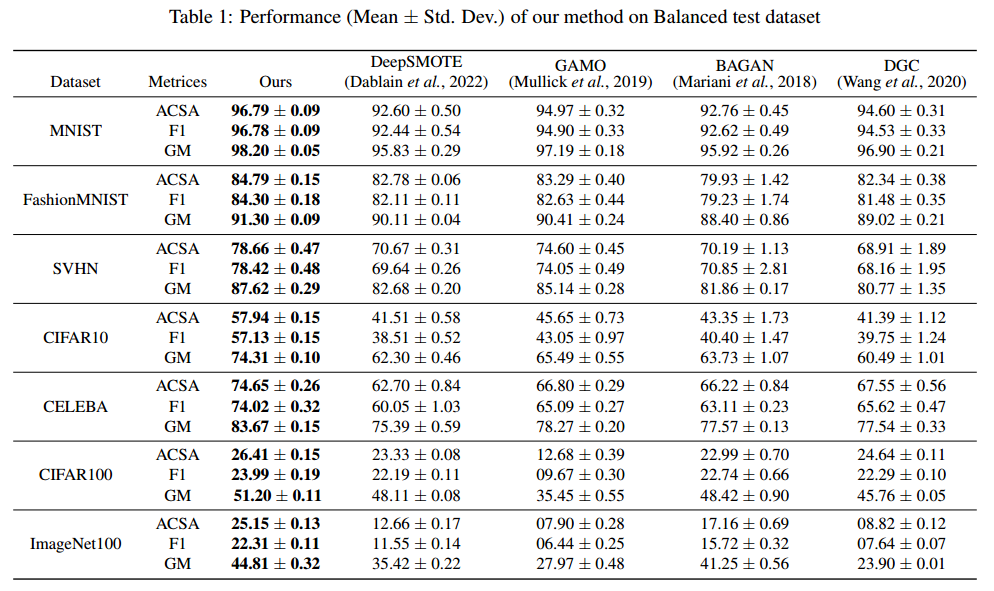
Experimental Results
제안한 모델이 다른 모델에 비해 성능이 얼마나 좋은지 확인해보도록 하겠습니다. 다양한 Vision data를 사용하고, 성능평가 지표로는 ACSA, F1 score, GM 을 사용하였습니다.
저자가 제안한 모델이 확실히 성능이 좋은 것을 알 수 있습니다!
또한 데이터의 질적 및 다양성을 측정하기 위한 지표로 Density와 Coverage를 사용했습니다. 이 지표들은 생성된 샘플이 실제 데이터 분포를 얼마나 잘 반영하고 있는지, 그리고 얼마나 다양한 샘플을 생성하고 있는지를 평가하는 데 유용합니다.
높은 Density 값은 생성된 샘플이 실제 데이터의 특정 영역에 집중적으로 분포되어 있음을 의미하며, 이는고품질의 샘플이 생성되고 있음을 시사합니다.
높은 Coverage 값은 생성된 샘플이 실제 데이터의 다양한 특성을 잘 반영하고 있음을 의미하며, 이는다양한 샘플이 생성되고 있음을 시사합니다.
확실히 제안된 모델이 전체적으로 다양한 데이터를 생성하고 있으며 실제 데이터 영역에 집중적으로 분포되어 있음을 알 수 있습니다!
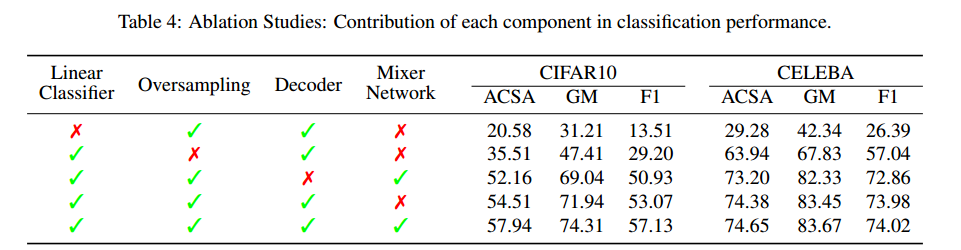
그리고 또한 Ablation studies를 통해 어떤 process에서 성능이 효과적이었던지도 파악할 수 있습니다.
Mixer Network를 사용한 모델과 사용하지 않은 모델에 대해서는 그다지 큰 차이가 나타나지 않았네요. (되게 신박한 아이디어라고 생각했는데, 성능 측면에서는 엄청난 효과를 불러일으키진 않았네요)
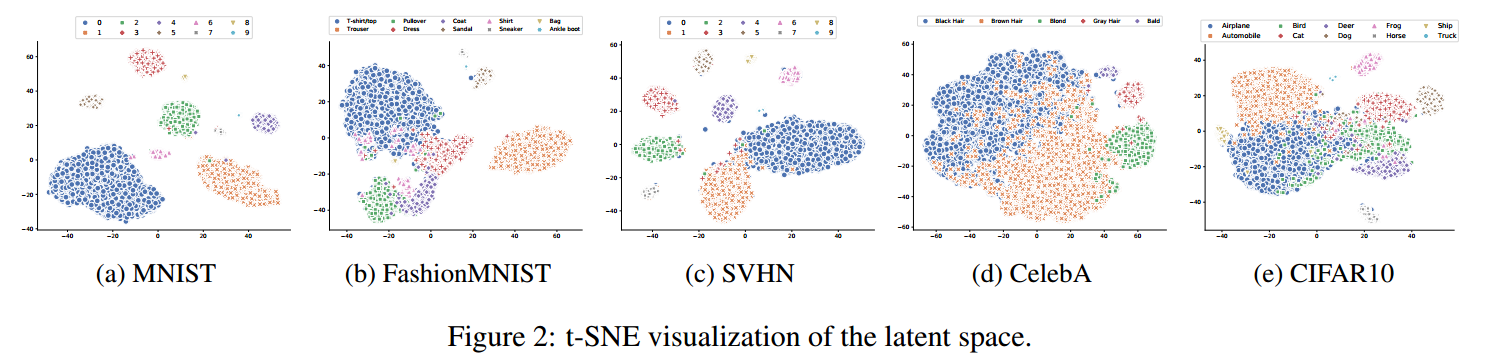
마지막으로 위 사진은 latent space에서 각 클래스의 분포를 나타낸 것인데, MNIST의 데이터 경우에는 확연하게 분리가 되어져 있는 것을 볼 수 있습니다.(degenerate representation을 방지하기 위해 class-preserving regularization을 추가해 각 클래스들간 latent space에서 겹침이 없어야 한다는 조건을 어느정도 만족시킨 것 같습니다.) (다른 data의 경우에는 linearly separable하진 않게 나오긴 했네요. 완벽하게 linearly separable 하다면 엄청난 모델이 될 것 같습니다!)
Conclusion
Minority class의 데이터를 oversampling하는데 클래스 보존의 제약을 걸어주고 다양한 데이터를 생성할 수 있게 하였습니다. Imbalanced data의 상황에서 이 모델은 아주 강력한 무기가 될 것 같습니다. 이런 concept을 vision data 뿐만 아니라 Tabular data에 대해서도 적용할 수 있으면 좋은 모델이 생길 수 있지 않을까 생각해 봅니다. Tabular data에 한번 적용시킬 수 있는 Idea를 고려해봐도 좋은 작업이 될 것 같습니다.