[ 목차 ]
SMOTE
이번 게시글에서는 Imbalanced data 상황에서 Oversampling 응용기법인 SMOTE 기법에 대해 다뤄보겠습니다.
기존의 Oversampling 기법은 minority class의 데이터를 단순히 복제시켜서 데이터의 균형을 맞추었지만, 단순히 복제하기 보단, minority class와 정보가 유사한 데이터를 생성하면 조금 더 모델이 학습을 잘 하지 않을까? 라는 생각에서 만들어 진 기법이 SMOTE입니다.
그러면 어떻게 데이터를 생성하냐? 이 기법에서는 단순히 minority class의 데이터를 복제하는 것이 아니라 기존 minority class의 데이터 포인트들 사이에서 새로운 데이터를 생성합니다. 이를 통해 모델이 더 일반화된 패턴을 학습할 수 있게 도와줍니다.
아래 사진을 보시면 불량과 정상 데이터에서 SMOTE 기법을 통해서 데이터를 복제하는 것이 아닌 minority class의 데이터 포인트들 사이에서 새로운 데이터를 생성한 것을 볼
수 있습니다.
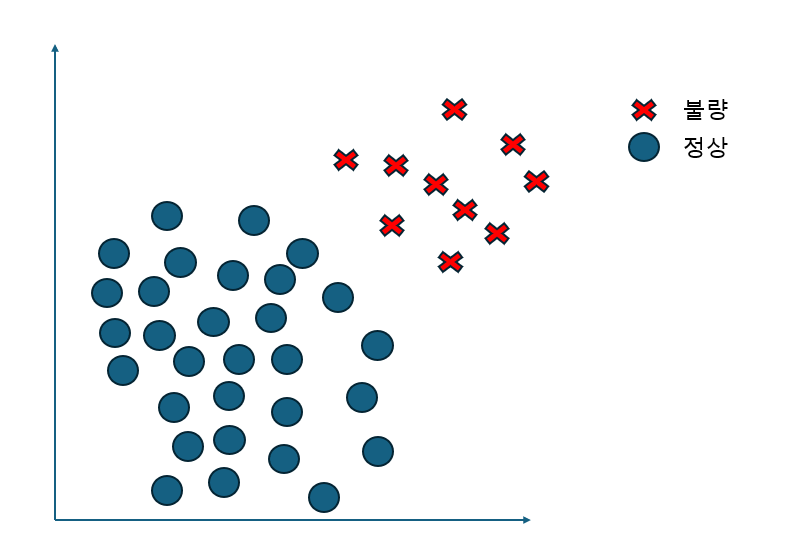
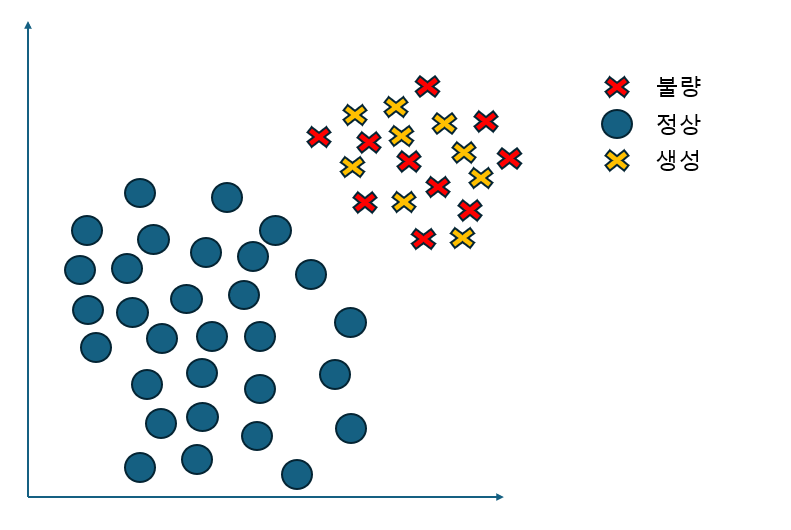
SMOTE의 작동 방식은 다음과 같습니다:
- 소수 클래스의 각 데이터 포인트에 대해: 이웃한 데이터 포인트를 찾습니다(예: k-NN 기법으로 k개의 이웃을 선택).
- 이웃한 포인트와의 차이를 계산하여, 그 차이를 무작위로 일정 비율만큼 더하여 새로운 데이터를 생성합니다.
위 내용을 조금 더 자세하게 설명드리도록 하겠습니다.


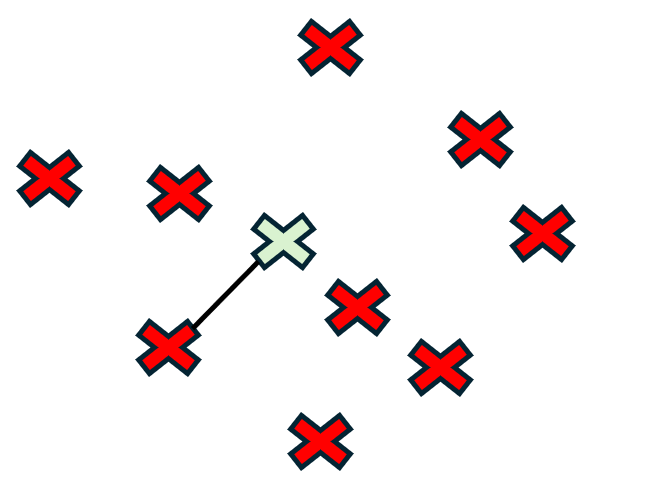
불량 데이터 중에서 하나를 무작위로 선택하는데 저 초록색이 선택되었다고 하겠습니다. 그 후 nearest neighbors를 선택해야 하는데 이때 k=3이 선택되었다고 하겠습니다. 그러면 우측 사진처럼 초록색 데이터와 가장 가까운 데이터 3개가 선택됩니다. 그 후 3개 중 한개를 랜덤으로 선택하고 그 직선 사이에서 데이터를 생성하게 됩니다. New data= X+u*(X(nn) - X). 이때 X : 기존의 데이터 포인트(초록색), X(nn) : 선택된 데이터 포인트 , u : 0과 1사이의 범위를 가지는 uniform distribution 입니다.
[New data 생성하는 법]
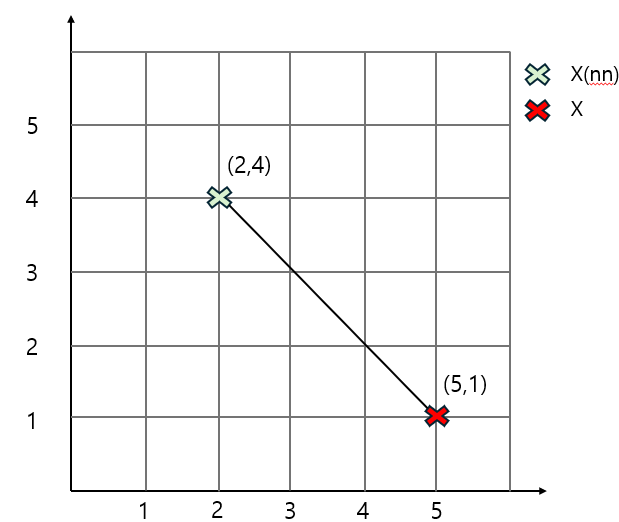
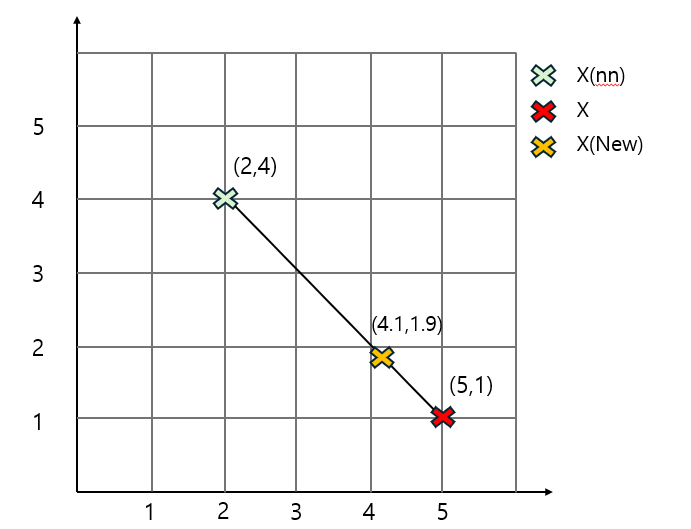
New data= X+u*(X(nn) - X)
= (5,1) + 0.3((2,4)-(5,1))
= (4.1,1.9)
이렇게 두 점 사이의 직선에서 새롭게 데이터를 생성할 수 있습니다.
SMOTE 기법을 사용하여 기존의 Oversampling방식과 다르게 단순히 복제하지 않고, minority class의 데이터의 직선사이에서 새로운 데이터를 생성하여 정보가 유사한 데이터들을 다양하게 생성할 수 있습니다. 그로 인해 과적합(overfitting)을 방지할 수 있고, 모델의 성능을 향상 또한 기대해볼 수 있습니다.
감사합니다.
참고문헌
'머신러닝' 카테고리의 다른 글
| [머신러닝] 유전 알고리즘(Genetic Algorithm) (1) | 2024.09.13 |
|---|---|
| [머신러닝] Oversampling & Undersampling (0) | 2024.09.11 |
| [머신러닝] Graphical Models (2) | 2024.05.20 |